
Introduzione
Nel mondo dell’AI generativa siamo ormai abituati a pensare in termini di prompt testuali e immagini generate, ma sempre più spesso il confine tra testo e immagine diventa bidirezionale.
Da un lato chiediamo a un modello di creare immagini a partire da parole (T2I, text-to-image), dall’altro iniziamo a usare modelli capaci di capire immagini e tradurle in testo (I2T, image-to-text).
È proprio in questo spazio ibrido che entrano in gioco i modelli Vision-Language (VL), e che nasce l’esperimento di cui parlerò in questo post: un workflow reale, eseguito in locale, che combina comprensione visiva, meta-prompting e generazione fotorealistica, senza dimenticare una riflessione necessaria sui diritti delle immagini generate.
Cosa sono i modelli Vision-Language (VL) e perché sono importanti
I modelli Vision-Language sono modelli multimodali in grado di elaborare immagini e testo nello stesso spazio semantico.
Non si limitano a “vedere” un’immagine, ma sono in grado di:
- descriverla in linguaggio naturale
- rispondere a domande sul suo contenuto
- estrarne dettagli strutturati
- usarla come contesto per ragionamenti più complessi
Questa capacità li rende fondamentali non solo per applicazioni “creative”, ma anche per analisi, automazione, accessibilità e controllo qualità.
Qwen3-VL
Tra i modelli VL più interessanti emersi di recente c’è Qwen3-VL, sviluppato dal team Qwen di Alibaba.
Il motivo principale per cui è rilevante per questo blog non è solo la qualità delle descrizioni, ma un aspetto molto concreto:
Qwen3-VL è open-weight.
Questo significa che:
- può essere eseguito in locale
- può essere integrato in workflow personalizzati (ad esempio in ComfyUI)
- consente sperimentazione reale, senza dipendere da API proprietarie
Rispetto a modelli come Gemini 3 o GPT-4o, Qwen3-VL eseguito in locale mostra limiti evidenti sul piano della conoscenza generale e del ragionamento avanzato, ma sul piano pratico della descrizione visiva è piuttosto solido, soprattutto se guidato con prompt ben progettati.
Z-Image e Z-Image Turbo: velocità, fotorealismo e open source
Se Qwen3-VL copre il lato I2T, serve poi un modello capace di trasformare testo in immagini con qualità elevata.
Qui entra in gioco Z-Image, in particolare la sua variante Turbo.
Z-Image Turbo ha due caratteristiche che lo rendono estremamente interessante:
- È open source / open weight, disponibile su GitHub e Hugging Face
- È estremamente efficiente, nonostante una dimensione di circa 6 miliardi di parametri
Nei test pratici Z-Image Turbo si distingue per:
- velocità di generazione molto elevata
- uso contenuto di VRAM
- fotorealismo notevole, soprattutto su soggetti umani e scene realistiche
È importante chiarire che non tutti i modelli Z-Image sono open source: in particolare le varianti base (non-distilled) e edit (image-to-image avanzato) non sono ancora rilasciate in forma open.
Questo è uno dei motivi per cui l’esperimento descritto in questo post passa volutamente dal testo, invece che da un vero flusso I2I.
Un workflow ComfyUI: da immagine a prompt, da prompt a nuova immagine
A questo punto abbiamo i due mattoni fondamentali:
- Qwen3-VL per analizzare un’immagine e produrre un prompt testuale
- Z-Image Turbo per generare una nuova immagine a partire da quel testo
Per realizzare il workflow, sono partito da alcuni esempi realizzati da Pixaroma e condivisi sul relativo canale Discord. Su Youtube sono disponibili interessanti tutorial (in particolare Ep 71 e Ep 72 sono rilevanti in questo caso) che comprendono anche tutti i link alle varie risorse. In ogni caso, il workflow eseguito segue sostanzialmente questa logica:
- immagine di input
- nodo Qwen3-VL → descrizione testuale
- eventuale modifica / miglioramento del prompt
- flusso T2I basato su Qwen3 + Z-Image Turbo
L’idea è quella di prendere ispirazione da un’immagine esistente per generarne una nuova, simile ma non identica.
Questo si collega direttamente al filo conduttore di Aladino Digitale: la lampada è l’AI, il desiderio è il prompt — e se il desiderio è formulato male, il risultato può essere molto diverso da quello sperato.
Usare un modello VL per ottenere un primo prompt “ben fatto” consente di:
- superare difficoltà linguistiche
- partire da una descrizione semanticamente ricca
- concentrarsi sugli elementi davvero salienti
Inoltre, il risultato finale non è una copia, ma una nuova immagine:
potenzialmente più libera da vincoli, e facilmente adattabile a:
- formati diversi (verticale, orizzontale, social-first)
- cambi di stile
- reinterpretazioni fotorealistiche di immagini stilizzate o cartoon
Questo approccio è una sorta di surrogato dei modelli edit, in attesa che Z-Image Edit venga rilasciato in forma open.
Focus: il nodo custom QwenVL in ComfyUI
Uno degli elementi chiave del workflow è il nodo custom ComfyUI-QwenVL.
Questo nodo permette di interrogare Qwen3-VL con diversi preset_prompt, ovvero prompt predefiniti pensati per ottenere descrizioni con livelli di dettaglio differenti.
Per avere un’idea di come il modello Qwen3-VL venga interrogato dal nodo di ComfyUI, tra i file di configurazione si possono leggere i prompt completi per i vari Preset (in particolare Simple Description, Detailed Description, Ultra Detailed Description, Cinematic Description e Detailed Analysis che useremo più avanti):
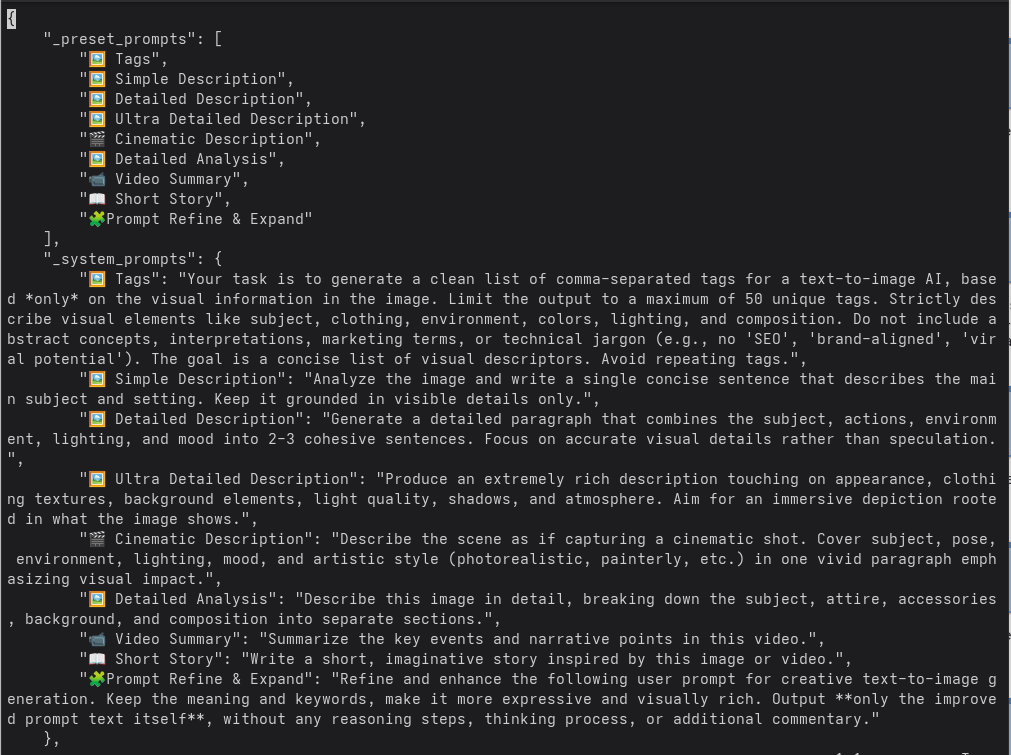
La differenza tra i risultati ottenibili con questi preset non è solo quantitativa (più o meno parole), ma qualitativa: cambia il tipo di attenzione che il modello dedica a composizione, luce, soggetti, atmosfera.
Un aspetto particolarmente potente è la possibilità di definire nuovi preset, semplicemente aggiungendo prompt personalizzati in un file di configurazione.
Questo apre la porta a un controllo artistico molto fine: ad esempio, enfatizzare outfit, materiali, espressioni o elementi narrativi specifici.
Un miglioramento interessante — che non escludo di implementare con una PR — sarebbe consentire l’output in formato JSON, così da meglio separare semanticamente elementi come soggetto, ambiente, stile e illuminazione.
Setup sperimentale e immagine di test
E’ dunque giunto il momento di provare il workflow presentato. Ho selezionato l’immagine di riferimento da usare per i test attingendo dal portfolio di Milagro:

Le prove sono state eseguite interamente in locale, sulla mia macchina basata su AMD Strix Halo, senza ricorrere ad API cloud o servizi esterni. Al solito, questo è un aspetto importante: al netto del non determinismo AI, l’esperimento è riproducibile e non dipende da infrastrutture proprietarie.
Ho configurato Z-Image Turbo (versione con precisione bf16) perché generasse immagini da 2.25 MP (1536 x 1536) in 5 step con sampler dmpp_sde e scheduler beta; per tutti gli altri elementi della configurazione (inlcuso Qwen3 4B come text encoder per processare i prompt) ho mantenuto i valori di default del workflow.
💡 Suggerimento:
ComfyUI salva di default il workflow completo utilizzato per la generazione delle immagini dentro i metadata dell’immagine stessa. Puoi dunque importare alcune delle immagini che trovi qui sotto (la versione.pngin alta risoluzione) dentro la tua installazione di ComfyUI e rieseguire facilmente i test.
In termini di tempi di esecuzione sulla mia macchina, il flusso completo ha richiesto circa un minuto e mezzo, diviso grossomodo in 30 secondi per la parte I2T (Qwen3-VL che genera il testo a partire dall’immagine in input) e un minuto per la parte T2I (quasi completamente spesi in fase di sampling, circa 11~12 secondi a step). I tempi di generazione dell’immagine dipendono fortemente dalla dimensioni dell’immagine richiesta e dunque dalla memoria allocata nello spazio latente; sul mio hardware, scendendo a 1MP di risoluzione (1024 x 1024) i tempi di generazione si riducono ad un terzo, circa 20 secondi.
Prove con i diversi preset
Per cominciare, ho eseguito varie prove configurando il nodo QwenVL affinché utilizzasse il modello Qwen3-VL-Instruct da 4 miliardi di parametri con numero massimo di token pari a 2048 (così da evitare troncamenti) e differenti preset.
Qwen3-VL-4B-Instruct con Simple Description
La descrizione testuale generata con il preset Simple Description rispecchia le attese (una singola frase concisa), fa riferimento a due auto Porsche di colore corretto e fornisce alcune indicazioni di massima riguardo la scena, il paesaggio e il meteo.
Two classic Porsche sports cars—a black 911 Turbo and a white 911—parked on an asphalt lot against a backdrop of rugged mountains under a dramatic, cloudy sky at dusk.
L’immagine generata a partire dal testo, utilizzato come prompt, ne segue le indicazioni correttamente: abbiamo due classiche Porsche 911, il riferimento al parcheggio porta ad avere strisce bianche a terra, le montagne e il cielo sono realistici ma necessariamente differenti da quanto osservabile nell’immagine di riferimento.

Qwen3-VL-4B-Instruct con Detailed Description
La modalità Detailed Description dovrebbe produrre un paragrafo dettagliato di 2-3 frasi che combini aspetti quali soggetto, azione, ambientazione, composizione / illuminazione e mood dell’immagine. Nel nostro caso otteniamo:
Under a vast, moody sky streaked with twilight hues of orange and gray, two iconic Porsche sports cars—a sleek black modern model and a classic white vintage coupe—rest side by side on an asphalt overlook, their polished surfaces reflecting the fading light as distant mountains loom behind them; the scene exudes quiet power and timeless elegance, capturing a moment where engineering heritage meets contemporary performance against nature’s dramatic backdrop.
Il linguaggio è sicuramente più ricco rispetto al preset Simple, l’abbondante uso di aggettivi contribuisce a definire meglio l’atmosfera e l’emozione che l’immagine dovrebbe trasmettere; inoltre viene recepito il fatto che le auto sono due modelli differenti, per Qwen la nera più moderna e la bianca classica / vintage.
L’immagine generata a partire dal testo è effettivamente un po’ più espressiva, ad esempio per i colori del cielo. Abbiamo sempre le strisce bianche sull’asfalto.

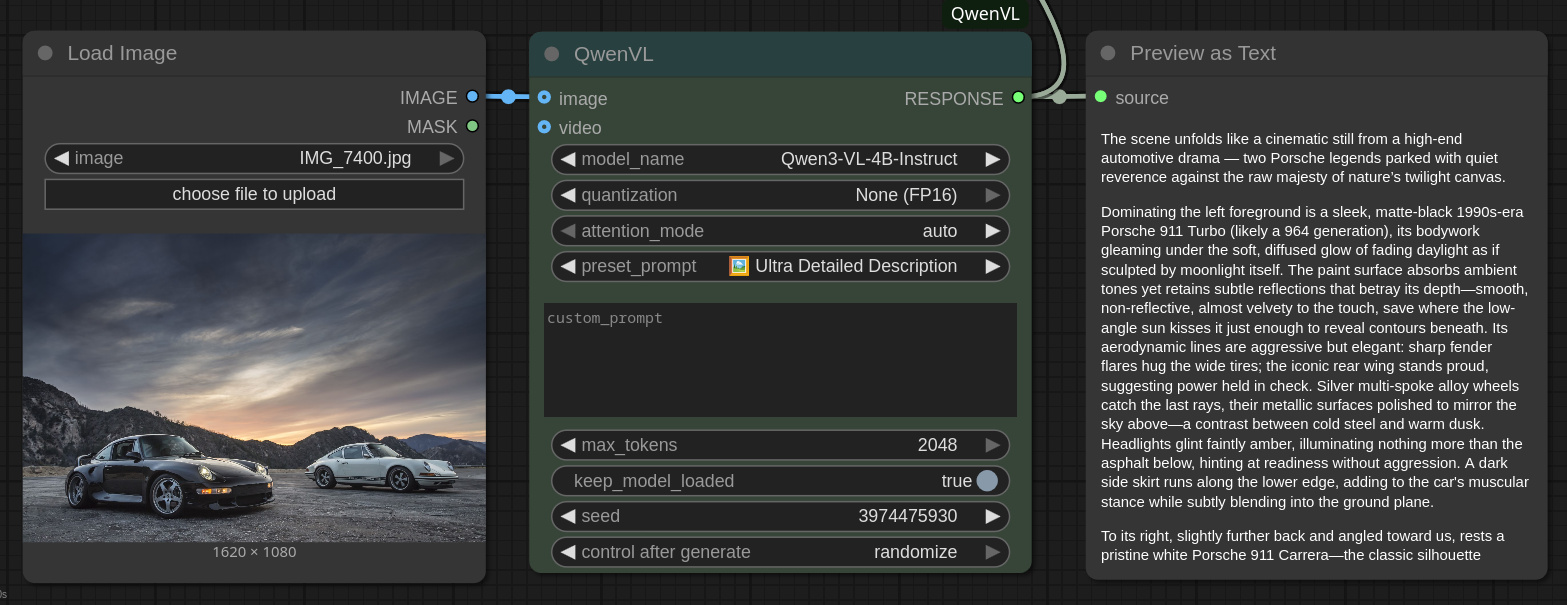
Qwen3-VL-4B-Instruct con Ultra Detailed Description
Il passaggio al preset Ultra Detailed Description, il cui prompt richiede una descrizione estremamente ricca che punti ad una rappresentazione immersiva, porta ad un testo generato di una decina di periodi. Se da un lato il modello coglie dettagli estetici dei veicoli, le luci accese di uno dei due, etc., dall’altro sembra quasi lanciarsi in interpretazioni al limite del filosofico sul significato dell’immagine. Da un punto di vista linguistico, il testo prodotto è comunque ben oltre quanto un umano (nativo nella lingua prescelta) avrebbe realisticamente scritto per descrivere un’immagine.
The scene unfolds like a cinematic still from a high-end automotive drama—two Porsche legends poised against nature’s grandeur under a sky that whispers of twilight’s final sigh. Dominating the left foreground is a matte-black 1990s-generation Porsche 911 (likely a Turbo or Carrera RS variant), its glossy surface absorbing ambient light yet reflecting it with deep, velvety intensity. The car's bodywork gleams subtly as if kissed by moonlight—or perhaps dawn’s last blush—that bleeds across the horizon. Its aerodynamic curves are sculpted into aggression: sharp lines along the fenders taper to muscular wheel arches housing multi-spoke alloy wheels polished to mirror-like perfection; each spoke catches the fading glow, casting faint geometric reflections onto the asphalt below. A prominent rear spoiler flares upward, hinting at hidden power beneath this sleek shell. Headlights illuminate softly—their circular halos glowing amber-yellow—as though ready to pierce darkness before they’ve fully surrendered their duty to dusk. Below them, the front bumper integrates subtle air intakes while maintaining clean elegance. Even the side skirts appear custom-fitted, suggesting performance tuning beyond factory specs—a whispered promise of raw mechanical prowess. To its right, slightly receding but equally commanding, sits another icon—an immaculate white 1970s-era Porsche 911 coupe. This classic beauty exudes timeless charm through minimalist design language. Its paint job shimmers almost ethereal under soft illumination, catching every contour without glare—even where shadow falls upon it—it retains luminosity thanks to careful lighting management inherent within the composition itself. Along the lower edge runs a thin black stripe bearing “PORSCHE” embossed delicately above the rocker panel line—an elegant signature acknowledging heritage rather than rebellion. Silver-rimmed wheels echo those seen earlier but carry different weight—they feel older, more nostalgic—and paired perfectly with chrome trim accents around windowsills and door handles which glint warmly despite surrounding gloominess. Tail lights blink gently off-key, signaling readiness even now when motion has ceased entirely. Behind these machines looms a rugged mountain range stretching far into distance. Their slopes rise steeply toward jagged peaks draped lightly in misty haze, covered partially in sparse vegetation clinging tenaciously to rocky outcrops. Bare trees dot sparsely scattered patches near ridgelines, standing sentinel amidst silence. Farther back, layers of hills fade progressively until only silhouettes remain visible against the vastness behind them. Above all lies the most arresting element —the heavens themselves. Thick clouds swirl lazily overhead, swirling patterns resembling smoke caught mid-motion, darkened grey-blue tones broken intermittently by streaks of pale gold-orange radiance seeping between creases. These wisps form delicate veils over distant horizons where sun dips low enough to cast long fingers of warm color directly downward—not quite sunset per se—but something closer to pre-dusk calmness. Light filters diffusely here, creating gentle gradients instead of harsh contrasts. Shadows stretch dramatically outward from both vehicles’ undersides and edges, elongated due to camera angle combined with time-of-day positioning. They don’t overpower features; instead, they frame forms precisely, enhancing dimensionality and grounding presence firmly among earthbound reality. As one gazes deeper, attention shifts naturally towards how everything interacts harmonically—with no single object dominating space except perhaps the two Porsches who stand shoulder-to-shoulder atop concrete terrain speckled unevenly with gravel bits and small stones. That pavement feels worn down but sturdy, textured irregularities contrasting sharply with smooth surfaces of cars' bodies. It serves not merely as stage floor but also anchor point anchoring entire universe together visually. This photograph captures more than mere objects—it encapsulates emotion: awe mixed with reverence. There's quietude amid dynamic energy implied silently by parked state juxtaposed against looming mountains awaiting wind-driven action. One senses anticipation lurking just outside frame boundaries waiting patiently… Perhaps tomorrow morning will bring racing tires gripping tarmac again? Or maybe simply appreciation of craftsmanship etched deeply into metal skin? In essence, we witness not just automobiles but living sculptures born from engineering genius placed deliberately beside natural splendor—all bathed simultaneously in atmospheric grace whose warmth lingers longer than any engine note ever could. Every curve, hue, texture speaks volumes about artistry fused seamlessly with function. And so does the moment suspended forever—in perfect balance-between human ingenuity and elemental majesty.
In termini di resa fotografica, l’immagine prodotta da Z-Image interpretando (attraverso Qwen3) il prompt qui sopra migliora sicuramente il risultato rispetto ai casi precedenti sia come qualità dei dettagli che come somiglianza all’originale, pur rimanendo comunque distante. Alcuni dei dettagli presenti nel prompt (la scritta PORSCHE sull’auto bianca, ad esempio) risultano mancanti.

Qwen3-VL-4B-Instruct con Cinematic Description
Il prompt associato al preset Cinematic Description richiede la generazione di un paragrafo vivido ed effettivamente nulla da dire in fatto di intensità e coinvolgimento della descrizione qui sotto:
In this cinematic widescreen composition, two legendary Porsche sports cars — a sleek, matte-black 911 Turbo RSR on the left and a pristine white classic 911 Carrera with racing stripes on the right — stand poised like silent warriors against an apocalyptic twilight sky streaked with bruised purples, deep grays, and molten orange near the horizon. The black machine dominates foreground space, its aggressive stance accentuated by custom alloy wheels and lowered suspension; headlights glow warmly, casting sharp reflections across the cracked asphalt that hints at rugged terrain or abandoned airstrip. Behind them, jagged mountain ridges loom under a vast, moody canvas of clouds swirling above, their silhouettes softened yet imposing. As dusk settles, ambient light bathes both vehicles in dramatic chiaroscuro: highlights glint off chrome trim and glossy paintwork while shadows deepen into mystery beneath the chassis. This is not merely photography—it’s theater: tense, reverent, evocative—where mechanical elegance meets raw natural drama. Shot with hyperreal precision but rendered through subtle film grain and selective color grading to mimic high-end cinematography, every curve and crease pulses with narrative weight. A contemplative stillness pervades, inviting viewers to imagine engine revs echoing unseen—or perhaps just silence between legends. It feels less like a photograph and more like a frame from a grand automotive epic set for eternity atop the edge of the world.
I colori, le ombre, etc dell’immagine generata rispecchiano, almeno in parte, la poesia del testo. Chiaramente il preset in questo caso influenza esplicitamente la resa finale, tuttavia complice la tipologia dell’immagine di riferimento, in qualche modo “cinematografica” già di per sè, abbiamo in generale una bella foto.

Qwen3-VL-4B-Instruct con Detailed Analysis
In modalità Detailed Analysis ci si aspetta che il modello VL produca una descrizione dettagliata e strutturata, divisa in sezioni separate per i vari aspetti. Effettivamente il lungo e ricco testo ottenuto isola e approfondisce soggetto, accessori e “estetica”, sfondo e composizione dell’immagine. Otteniamo tanti dettagli sui due veicoli le cui differenze sembrano venire recepite da Qwen3-VL. Inoltre, finalmente abbiamo un’approfondita parte del prompt dedicata alla composizione dell’immagine, comprendente posizionamento dei soggetti, palette di colori e tecniche di illuminazione, ottica (tipo di obbiettivo) utilizzata, etc.
Certainly! Here is a detailed breakdown of the provided image:
—
**Subject:**
The primary subjects are two Porsche sports cars parked on an open asphalt surface.
- **Left Car (Foreground):**
- A modern black Porsche 911 Turbo or similar high-performance model.
- Features include:
- Aggressive aerodynamic bodywork with prominent front air intakes and side skirts.
- Large, multi-spoke silver alloy wheels — likely custom aftermarket rims given their design and finish.
- Brightly lit headlights; turn signals also illuminated.
- Low-slung stance suggesting performance tuning or lowered suspension.
- Rear spoiler visible above the trunk lid for enhanced airflow control.
- **Right Car (Background / Right Side):**
- An older-generation white Porsche 911, appearing to be from the late '70s/early '80s era (possibly a 911 Carrera RS).
- Distinctive features:
- Classic rounded fenders and iconic curved hoodline.
- Black racing stripes running along the lower sides, bearing “PORSCHE” lettering.
- Simple five-spoke steel wheels typical of its time period.
- Clean lines without aggressive modifications compared to the left car’s sporty aesthetic.
Both vehicles showcase timeless German engineering while contrasting generations through styling cues and mechanical evolution.
---
**Attire & Accessories:**
There is no human presence in either vehicle or around them—no driver, passenger, crew members, nor any individuals wearing clothing or carrying gear. The focus remains entirely on the automobiles themselves as objects of admiration and technical excellence.
Accessories associated directly with each car:
- Left car has LED daytime-running lights integrated into headlight assemblies and possibly additional fog lamps under the bumper area.
- Both feature factory OEM badges (“Porsche”) prominently displayed near rear wheel arches and center of hoods respectively.
- No personal items like helmets, gloves, tools, etc., appear present within view.
No wearable apparel exists since there's nobody depicted visually interacting with these machines.
---
**Background Elements:**
Behind the two Porsches stretches dramatic natural scenery:
- Rolling mountain ranges stretch horizontally across mid-ground behind the scene.
- Mountains vary slightly in elevation but maintain consistent rocky textures covered sparsely by vegetation such as scrub brush or small trees clinging to slopes.
- Horizon line marks where sky meets land at dusk/dawn transition zone—a soft gradient between warm orange-pink tones near ground level fading upward toward cooler grays/blues overhead.
- Sky dominates upper half of frame filled densely with dynamic cloud formations that suggest motion blur effect captured via long exposure technique during twilight hours.
Overall atmosphere evokes solitude, grandeur, power—and perhaps nostalgia juxtaposed against innovation represented by both models’ designs.
---
**Composition Analysis:**
This photograph employs strong compositional techniques designed to highlight contrast and visual interest among elements presented.
- **Leading Lines:** Asymmetrical placement positions viewer eye naturally drawn first towards dominant foreground object—the sleek black turbo sedan—with secondary attention shifting rightward onto classic white coupe due to spatial depth cue created by perspective convergence point extending off-screen horizon.
- **Framing Techniques Used:**
- Wide-angle lens utilized which captures expansive vista including entire mountainscape beneath massive canopy of clouds stretching beyond edges of canvas.
- Use of negative space effectively isolates focal points allowing individual characteristics of each automobile stand out clearly despite being placed apart geographically relative to one another.
- **Color Palette Strategy:**
- Dominant dark gray/black hues dominate automotive surfaces creating sense of sophistication yet grounded realism.
- White Porsche provides stark tonal opposition enhancing visibility and emphasizing elegance inherent in vintage appeal.
- Warm sunset glow subtly illuminating distant peaks adds emotional warmth counterbalancing otherwise somber mood established by overcast skies.
- **Light Directionality:**
- Ambient light originates low angle close to horizon indicating golden hour lighting conditions ideal for accentuating contours and metallic finishes.
- Reflections caught upon glossy paint jobs confirm reflective quality characteristic of premium manufacturing materials used in original construction.
In summary, careful manipulation of color scheme, directional illumination, framing balance—all contribute significantly to elevating narrative impact surrounding relationship between past legacy and future aspirations embodied by these legendary European supercars set against majestic backdrop of nature’s scale.
---
Let me know if you’d like further analysis related specifically to camera settings, editing choices, symbolism, or historical context regarding the specific models shown here!
[Note: Since neither vehicle appears explicitly labeled "Carrera" or other exact model names based solely on appearance alone unless confirmed later.]
Da notare che la versione del custom node QwenVL utilizzata non sembra effettuare opportuna pulizia del testo generato dal modello prima di ritornarlo all’utente: troviamo infatti due frasi tipiche di contenuti generati da AI all’inizio (un generale ringraziamento e accettazione della richiesta) e alla fine (offerta di approfondire l’argomento). In ogni caso, complice anche il formato quadrato esplicitamente richiesto in fase di generazione, l’immagine generata sembra non rispettare appieno le indicazioni riguardo l’inquadratura: la ripresa avrebbe potuto essere più grandangolare e l’uso della tecnica dello spazio negativo è sostanzialmente assente, tanto che la scritta PORSCHE sull’auto bianca è quasi completamente coperta dall’auto nera.

Qwen3-VL-8B-Instruct con Detailed Analysis
Decido a questo punto di provare ad utilizzare un modello Qwen3-VL più grande (8B) per verificare se si ottengano risultati migliori.
Of course. Here is a detailed breakdown of the image, organized by your requested categories.
---
**Subject:**
The primary subjects are two iconic Porsche 911 sports cars positioned on an open asphalt surface against a dramatic mountain backdrop at dusk or dawn.
- **Car on the Left (Foreground):** A black Porsche 993 Turbo S (or similar high-performance variant), characterized by its aggressive styling. Key features include:
- Large rear spoiler integrated with the roofline.
- Wide fenders and muscular bodywork typical of the "Turbo" models from that era.
- Distinctive front air intakes below the headlights.
- Silver multi-spoke alloy wheels.
- The car’s headlamps are illuminated, casting a warm glow.
- **Car on the Right (Background/Distance):** A white classic Porsche 911 Carrera RS-style model, likely from the late 1970s to early 1980s. Features include:
- Classic round headlights.
- Black racing stripes running along the sides, bearing the word “PORSCHE” in capital letters.
- Smaller, more minimalist side mirrors compared to modern Porsches.
- Standard steelies or smaller-diameter alloys.
- Its lights appear off, emphasizing its silhouette as it recedes into the scene.
Both vehicles exude performance heritage and timeless design, creating a visual dialogue between generations of automotive engineering.
---
**Attire / Accessories:**
There are no people visible in the photograph, so there is no human attire to describe.
However, both cars serve as their own form of accessory within the frame:
- **Accessories for Car #1 (Black Turbo):**
- Custom widebody kit enhancing aerodynamics and aggression.
- Performance-oriented suspension evident through low stance.
- Factory or aftermarket wheel choice complementing its sporty character.
- Functional lighting system including fog lamps or auxiliary driving lights under the bumper.
- **Accessories for Car #2 (White Classic):**
- Racing stripe decals — not just cosmetic but historically significant for track use.
- Original factory bumpers and trim pieces consistent with period-correct restoration.
- Simple, functional door handles matching the vintage aesthetic.
Together, these elements function as narrative devices—showcasing evolution while honoring tradition.
---
**Background:**
The setting provides immense atmosphere and context:
- **Sky:** Dominated by heavy clouds streaked horizontally across the upper portion, suggesting either fast-moving weather systems or long-exposure photography capturing motion blur over time. Near the horizon, soft gradients transition from deep gray-blue above to pale orange-yellow where sunlight breaks through, indicating sunset or sunrise.
- **Mountains/Ridges:** Jagged, rocky ridgelines stretch behind the cars, adding depth and scale to the landscape. Their muted earth tones contrast beautifully with the vibrant sky colors. Sparse vegetation clings precariously to some slopes.
- **Ground Surface:** An expansive flat paved area—a possible airstrip, test track, or remote parking lot—which allows full appreciation of both vehicles without obstruction. Cracks and texture suggest age or exposure to environmental conditions.
This natural environment serves as a powerful foil to the man-made machines; it evokes solitude, raw power, and endurance—all qualities associated with legendary racecars like those depicted here.
---
**Composition:**
The photographer has crafted a carefully balanced and visually compelling arrangement using several compositional techniques:
- **Rule of Thirds & Diagonal Balance:** Both cars occupy distinct thirds—one near left foreground, one right mid-ground—with space allocated around them to create breathing room and avoid clutter. This creates dynamic tension yet harmony between the pair.
- **Leading Lines & Depth Perception:** The road's edge curves gently toward the mountains, subtly guiding viewer attention inward and upward towards the light source. Additionally, the diagonal alignment formed by the cars’ orientation adds energy and movement even though they’re stationary.
- **Contrast Through Color & Lighting:** High contrast exists between the dark storm-laden skies versus the glowing horizons. Similarly, the matte finish of the black car contrasts sharply with the bright reflective surfaces of the white vehicle. Warm ambient light highlights parts of each car differently—the driver-side mirror glows warmly on the black car, whereas shadows dominate much of the white car—but both catch enough reflected hues to remain cohesive.
- **Framing & Negative Space:** The vast empty spaces surrounding the main subjects emphasize isolation and grandeur. Mountains act naturally as framing borders, while negative space ensures focus remains squarely on the automobiles themselves rather than distracting details elsewhere.
In summary, this image successfully marries technical precision with artistic vision—to present not merely photographs of luxury supercars, but cinematic moments frozen forever amidst nature’s majestic drama. It tells stories about legacy, innovation, beauty, speed—and ultimately, passion—for what lies beneath every polished curve and gleaming panel.
La descrizione risulta più dettagliata della corrispondente prodotta dal modello 4B, ma il risultato finale al termine della fase di generazione della nuova immagine è solo leggermente migliore. In ogni case, forse la migliore immagine fino a questo punto.

Qwen3-VL-8B-Instruct con Cinematic Description
Per completare il quadro, vediamo cosa produce il workflow sempre col modello Qwen3-VL 8B e preset Cinematic Description:
Under a vast, brooding sky streaked with twilight’s bruised purples and molten golds, two legendary Porsche 911s stand poised like silent sentinels on an open asphalt plateau flanked by rugged, shadow-draped mountains—a cinematic tableau of power and elegance frozen at dusk. The foreground is dominated by a sleek, matte-black 993 Turbo S, its aggressive stance emphasized by low-slung lines, wide fenders, and gleaming multi-spoke wheels; headlights glow warmly against its dark form, casting sharp reflections that hint at motion even when still. To its right, slightly receding into atmospheric depth, rests a pristine white 964 Carrera RS, its classic curves softened yet defined by racing stripes and minimalist design—its own quiet intensity radiating from beneath the fading light. The dramatic chiaroscuro effect sculpts their forms: cool shadows pool under chassis while highlights dance across polished surfaces, creating tactile contrast between metallic sheen and weathered pavement. A sense of timeless rivalry or harmonious dialogue hangs heavy in the air—the black car roaring forward, the white gliding backward—as though they’re not merely vehicles but characters caught mid-narrative within this epic landscape. Shot in photorealistic precision with painterly composition, every detail—from tire texture to cloud wisps—is rendered with hyper-real clarity, evoking both documentary truth and romanticized mythos, where engineering meets artistry under skies painted for drama alone. **Visual Impact:** Stark contrasts, dynamic silhouettes, rich color gradients, deep textures, and emotional resonance through juxtaposition create a visually arresting moment suspended between speed and serenity — perfect for posterity.
La descrizione enfatizza l’impatto visivo atteso per l’immagine, tuttavia in generale il testo prodotto non si discosta in maniera significativa da quello prodotto dal modello più piccolo. Anche l’immagine generata appare molto simile (i fari dell’auto nera però sono accesi questa volta).

Meta-prompting: generare prompt a partire da prompt
Un’ulteriore evoluzione del workflow consiste nel non passare più un’immagine a QwenVL, ma una coppia di stringhe testuali:
prompt: una descrizione semplice (ad esempio ottenuta precedentemente con Simple Description)formula: un meta-prompt che chiede esplicitamente di generare un prompt con determinate caratteristiche.
Nel nostro caso, ho optato per richiedere un prompt ottimizzato per il fotorealismo derivante dalla sensazione che l’immagine sia una fotografia analogica 35mm. Ho chiesto a ChatGPT di aiutarmi a scrivere un prompt che generi un prompt che… e alla fine ho ottenuto questo:
Per favore analizza l'immagine allegata e scrivimi un prompt di miglioria specifico per trasformarla in una fotografia in stile analogico 35mm, con questi obiettivi: realismo estremo, forte drammaticità, atmosfera da pellicola vissuta, difetti coerenti con il film (grain, halation, flare, colori meno perfetti). Includi nel prompt specifico: tipi di grana realistica (fine/medium), halation attorno a luci e contrasti, leggero fading dei colori o tonalità vintage, vignettatura organica e bordi leggermente morbidi, micro-imperfezioni: polvere, graffi, disallineamenti, errori di esposizione o bilanciamento del bianco plausibili, elementi narrativi coerenti con la scena che aumentano la sensazione di “scatto su pellicola".
Opportunamente tradotto (da Gemini) e leggermente adattato per il campo Formula, ecco il nuovo prompt inserito nel workflow:
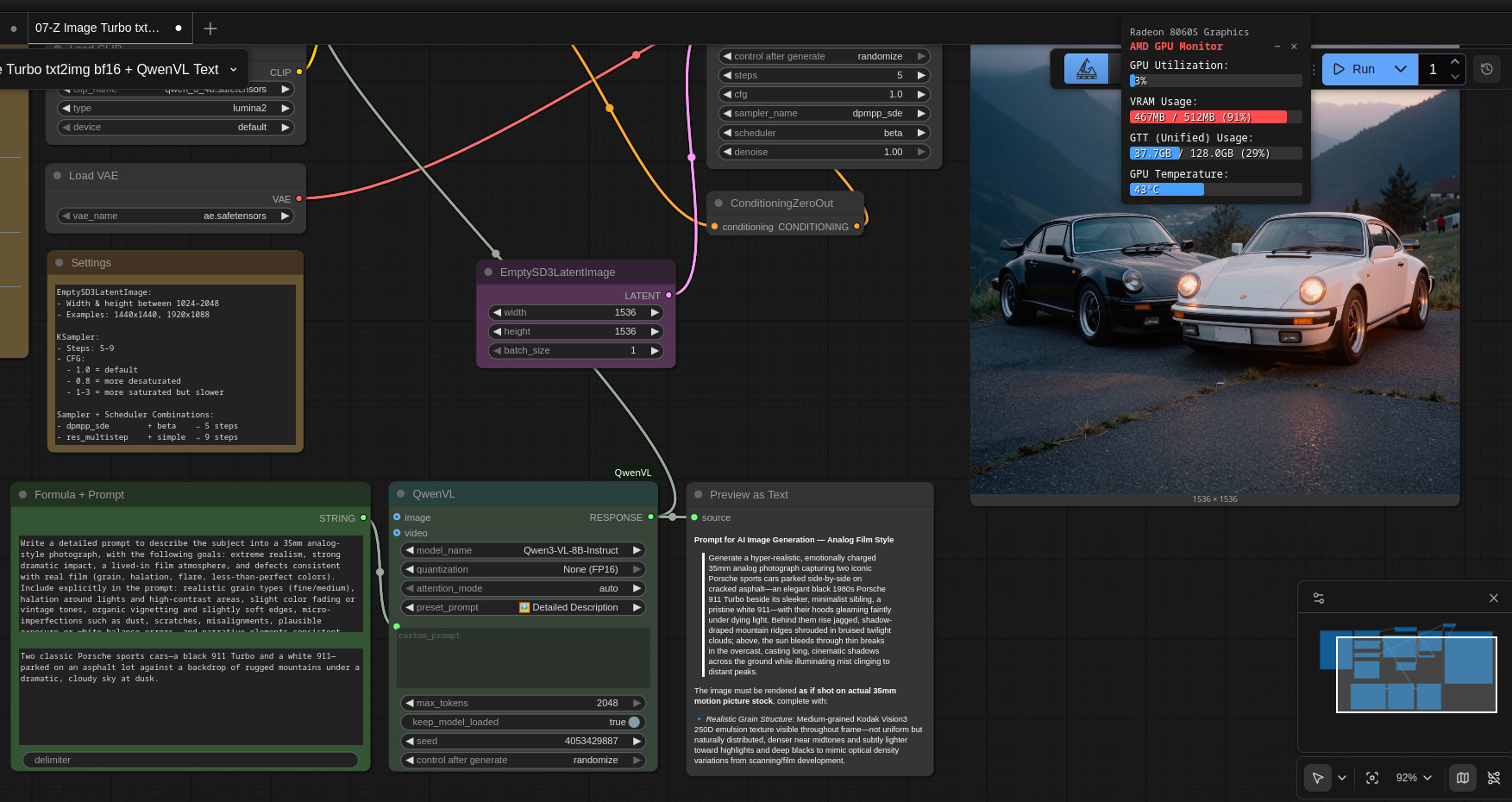
Un paio di esempi di immagini generate con preset Detailed Description a partire dal prompt semplice:


Diritti e copyright delle immagini generate: riduzione del rischio, non immunità legale
Dopo aver visto nel dettaglio come funziona un workflow image-to-text seguito da text-to-image, è naturale chiedersi se questo approccio rappresenti anche una sorta di “via d’uscita” dal punto di vista dei diritti nel copiare immagini. L’idea è seducente: invece di partire direttamente dall’immagine, la trasformo in testo; invece di modificare l’originale, genero qualcosa di nuovo. Ma quanto questa distanza tecnica corrisponde davvero a una distanza giuridica?
La risposta onesta è che I2T → T2I è uno strumento di mitigazione del rischio, non una garanzia legale.
Funziona bene quando viene usato per astrarre, interpretare, trasformare. Funziona molto meno — o per nulla — quando viene usato per ricostruire.
Per capire perché, bisogna chiarire un punto fondamentale: i diritti non proteggono il percorso tecnico, ma il risultato finale.
Il passaggio dal testo non “resetta” i diritti
Uno degli equivoci più comuni è pensare che il diritto protegga il mezzo — il file, i pixel, il formato. In realtà, sia nel diritto d’autore sia nel diritto all’immagine conta l’opera risultante, non il fatto che sia stata generata “a mano”, con Photoshop o con un modello AI.
Se un’immagine generata è:
- sostanzialmente simile a un’opera esistente
- riconducibile a una persona reale
- funzionalmente sostitutiva di un’immagine protetta
allora il fatto che sia passata da una descrizione testuale non costituisce una difesa automatica.
È vero però che I2T introduce una distanza semantica che, se gestita con criterio, rende più difficile arrivare a risultati “troppo vicini” all’originale. Ma questa distanza va costruita intenzionalmente, non data per scontata.
Diritto d’autore: quando la somiglianza conta più della tecnica
Nel caso delle immagini (e in particolare delle fotografie), il diritto d’autore tutela l’impronta creativa: composizione, luce, scelta del momento, inquadratura. Non serve una copia perfetta perché si parli di opera derivata: è sufficiente che un osservatore medio riconosca nell’opera nuova l’essenza di quella precedente.
Nel workflow I2T → T2I il rischio aumenta quando:
- la descrizione estratta dall’immagine è eccessivamente specifica
- il prompt ricostruisce la stessa posa, la stessa luce, lo stesso mood
- il risultato “sembra chiaramente quella foto, rifatta”
In questi casi, il passaggio intermedio dal testo non cambia la sostanza del problema.
Uso commerciale e sostituzione funzionale
C’è poi un aspetto spesso sottovalutato: la funzione dell’immagine, non solo la sua estetica.
Se un’immagine generata:
- sostituisce una fotografia esistente in un contesto commerciale
- replica uno standard visivo (stock, advertising, cataloghi, hero image)
si entra in un’area in cui il problema non è più solo creativo, ma economico. Anche senza una somiglianza perfetta, l’uso può essere contestato se l’immagine AI prende il posto di un contenuto protetto sul mercato.
Il workflow I2T → T2I non elimina questo rischio, soprattutto se viene usato con l’obiettivo implicito di “rifare la stessa cosa senza pagare i diritti”.
Persone reali e il nodo della model release
Qui vale la pena fermarsi un attimo, perché è uno dei punti più fraintesi.
Nel linguaggio della fotografia professionale, una model release è il consenso con cui una persona autorizza l’uso della propria immagine, soprattutto in ambito commerciale. Non riguarda il copyright della foto, ma il diritto all’immagine del soggetto ritratto.
Se una persona è riconoscibile, questo diritto non scompare perché:
- l’immagine è stata rielaborata
- l’immagine è stata generata da un modello AI
- si è passati da testo invece che da pixel
Questo vale anche nel workflow I2T → T2I.
Se l’immagine finale:
- riproduce una persona reale riconoscibile
- o una “controfigura evidente” (stessi tratti, stessa identità percepita)
il problema della model release rimane identico.
Per questo motivo, in ambito professionale, molte aziende preferiscono:
- usare persone completamente sintetiche
- evitare riferimenti a individui reali
- lavorare su volti deliberatamente non riconducibili a nessuno
Il flusso I2T → T2I può aiutare in questa direzione solo se l’obiettivo è creare persone nuove, non rifare persone reali “con un altro volto”.
Conclusioni (in ordine sparso)
- I modelli Vision-Language hanno un potenziale enorme, ben oltre la semplice descrizione di immagini
- La “lampada dell’AI” può essere usata anche per imparare a esprimere meglio i desideri : possiamo usare modelli Vision-Language per generare prompt iniziali a partire da immagini esistenti
- Il meta-prompting è uno strumento potente per migliorare i prompt senza diventare esperti linguisti: possiamo usare un LLM per creare un meta-prompt di ottimizzazione di un prompt/test esistente, e poi “applicarlo” a quanto ottenuto dal modello Vision-Language
- Z-Image Turbo riesce a produrre immagini estremamente realistiche con poche risorse e tempi ridotti
- Prompt più lunghi non garantiscono necessariamente risultati migliori: conta cogliere gli elementi salienti. I preset del nodo QwenVL per ComfyUI usati per le prove offrono alcuni punti di partenza per generare i prompt. A seconda dell’immagine input, è possibile personalizzare i preset o sostituirli completamente con prompt che focalizzino l’attenzione su aspetti specifici, ad esempio inquadratura, o dettagli dell’immagine (Qwen3-VL non ha mai notato che sull’auto nera ci sono due persone, per dire, e che hanno un finestrino aperto). Opportuna pulizia dei prompt generati dal modello Vision-Language prima di passarlo alla generazione dell’immagine consentirebbe ulteriori migliorie della resa finale.
- Qwen3-VL mostra alcuni limiti di conoscenza specifica, in questo caso auto Porsche; a memoria di chi ha scattato la foto, i due modelli sono 993 RUF Turbo R degli anni ‘90 (la nera) e 911 Singer (la bianca). Per la cronaca, Gemini 3 Pro che pure ha avanzate capacità Vision-Language, sicuramente oltre quelle di Qwen3-VL 8B, ha comunque correttamente identificato solo la Singer.
- Il flusso I2T + T2I non è un passpartout legale
Ma proprio questi limiti rendono l’esperimento interessante: è un esempio concreto di cosa si può fare oggi, in locale, con strumenti aperti — e di quanto spazio ci sia ancora per migliorare.
Come sempre, il genio della lampada ascolta… ma bisogna imparare a parlare la sua lingua.