
Negli ultimi mesi sto esplorando i limiti e le problematiche relative all’utilizzo di modelli locali per attività di coding agent. Non parlo solo di completamento del codice, ma di strumenti che leggono una codebase, eseguono comandi, modificano file, lanciano test e provano a risolvere un problema in autonomia.
A quel punto la domanda diventa inevitabile: come si misura davvero la qualità di un modello in questo scenario?
I benchmark classici sui modelli di linguaggio aiutano fino a un certo punto. Sapere che un modello è forte su HumanEval, MMLU, GPQA o su un generico “coding score” è interessante, ma dice poco su quello che succede quando lo metti dentro un agente, gli dai una issue reale, un repository non banale, una shell, dei test e gli chiedi di produrre una patch funzionante.
Per questo i benchmark della famiglia SWE-bench sono diventati così importanti. E per questo mi sono messo a guardare con attenzione SWE-bench Pro.
Non tanto per pubblicare un numero da leaderboard, ma per rispondere a una domanda molto più pratica:
Se eseguo lo stesso modello in locale con quantizzazioni diverse, quanto cambia davvero la capacità di risolvere task di coding agent?
Questo post è il primo pezzo del percorso. Racconta cos’è SWE-bench Pro, perché esiste, quali problemi prova a risolvere rispetto ai benchmark precedenti, e cosa significa provare a eseguirlo in locale.
I risultati veri arriveranno probabilmente più avanti, per ora proviamo a costruire un metodo.
Perché serve un altro benchmark
SWE-bench nasce con un’idea molto semplice e molto potente: prendere issue reali da repository GitHub reali e chiedere a un modello di generare una patch che risolva il problema.
Non quindi:
- scrivere una funzione isolata;
- completare poche righe di codice;
- rispondere a una domanda teorica;
- scegliere tra quattro opzioni.
Ma lavorare su una codebase vera.
In un task di SWE-bench il modello riceve una descrizione del problema, ha accesso al repository, deve modificare i file corretti e alla fine viene valutato eseguendo una suite di test. Se i test che prima fallivano passano e quelli che già passavano continuano a passare, la patch viene considerata corretta.
Questo è molto più vicino a quello che ci interessa quando parliamo di coding agent.
Il problema è che i benchmark, quando diventano popolari, iniziano anche a saturarsi.
Saturazione significa almeno tre cose:
- i modelli migliorano davvero e risolvono sempre più casi;
- gli strumenti attorno ai modelli vengono ottimizzati specificamente per quel benchmark;
- i task pubblici finiscono in dataset, esempi, discussioni, traiettorie, post, repository e materiale di training.
A quel punto diventa difficile capire quanto uno score misuri davvero capacità generale e quanto invece misuri familiarità, ottimizzazione sul benchmark o, nei casi peggiori, contaminazione.
Questo è diventato particolarmente evidente con SWE-bench Verified. Verified nasceva come subset più pulito e umanamente verificato di SWE-bench, composto da 500 problemi considerati risolvibili da sviluppatori reali. Per un certo periodo è stato uno dei riferimenti principali per confrontare modelli e agenti.
Poi però il benchmark è diventato talmente centrale da essere sempre meno informativo. Se i casi sono pubblici, discussi, riutilizzati e magari inclusi indirettamente nei dati di training, il numero finale continua a essere interessante, ma va letto con cautela.
SWE-bench Pro nasce anche da qui: dalla necessità di avere task più realistici, più lunghi, più vari e meno facilmente saturabili.
Cos’è SWE-bench Pro
SWE-bench Pro è un benchmark per valutare coding agent su task software di maggiore complessità rispetto a SWE-bench classico e Verified.
La differenza non è solo quantitativa, ma qualitativa. L’obiettivo è avvicinarsi di più a problemi da sviluppo software reale: codebase più complesse, linguaggi diversi, task più lunghi, modifiche che coinvolgono più file e patch meno banali.
La struttura del benchmark è divisa in tre insiemi principali:
- Public set: 731 task pubblici, rilasciati su Hugging Face;
- Commercial set: 276 task provenienti da repository proprietari di startup partner, non rilasciati pubblicamente;
- Held-out set: 858 task tenuti privati, pensati per misurare overfitting e generalizzazione futura.
Questa divisione è importante.
Il public set è quello che possiamo scaricare ed eseguire localmente. È utilissimo per esperimenti riproducibili, confronti tra configurazioni, studio degli errori e analisi metodologiche.
Ma proprio perché è pubblico non può essere considerato completamente immune alla contaminazione.
Il commercial set e l’held-out set servono invece a preservare una parte del benchmark fuori dalla portata diretta di training, tuning e ottimizzazioni pubbliche. Sono più adatti a misurazioni “da leaderboard” o a confronti controllati, ma non sono eseguibili liberamente in locale.
Quindi la prima cosa da chiarire è questa:
Eseguire i 731 casi pubblici di SWE-bench Pro è utile, ma non equivale a eseguire il benchmark privato completo.
Non è un dettaglio. È il tipo di distinzione che può cambiare completamente il significato di uno score.
Contaminazione: il problema non sparisce
SWE-bench Pro è stato progettato anche per ridurre il rischio di contaminazione. Ad esempio, i subset open source usano repository con licenze copyleft forti, mentre il subset commerciale contiene codice proprietario non rilasciato pubblicamente.
Questo aiuta, ma non rende magico il public set.
Se un task è pubblico, allora in linea di principio può finire:
- nei dati di training;
- in issue e discussioni online;
- in repository di esperimenti;
- in log di agenti pubblicati;
- in post tecnici;
- in dataset derivati;
- in patch usate per esempi e tutorial.
Quindi, se un modello ottiene un buon risultato sul public set, non possiamo automaticamente dire: “ecco la sua capacità su problemi mai visti”.
Però questo non significa che il public set sia inutile. Dipende dalla domanda.
Se voglio confrontare in assoluto due modelli frontier e dichiarare chi sia migliore in generale, la contaminazione è un problema serio.
Se invece voglio confrontare lo stesso modello in più quantizzazioni, sullo stesso hardware, con lo stesso agente, lo stesso prompt e lo stesso subset di task, allora il public set può essere estremamente utile.
In quel caso non sto cercando di misurare la capacità assoluta del modello nel mondo. Sto cercando di misurare una variazione relativa:
quanto degrada il comportamento agentico passando, ad esempio, da una quantizzazione più conservativa a una più aggressiva?
È una domanda molto pratica. Ed è esattamente il tipo di domanda che mi interessa per l’AI locale.
Quando un task si considera passato
Il funzionamento di base è questo.
Per ogni istanza del benchmark esiste:
- una descrizione del problema;
- un repository in uno specifico stato iniziale;
- una patch “gold”, cioè la soluzione attesa o di riferimento;
- una serie di test che devono passare dopo la correzione.
Il modello non deve produrre una spiegazione. Deve produrre una patch.
L’evaluator applica la patch al repository e lancia i test selezionati. In genere si distinguono due categorie:
- fail-to-pass: test che prima fallivano e che devono passare dopo la patch;
- pass-to-pass: test che già passavano e devono continuare a passare.
Una patch è considerata corretta solo se risolve il problema senza rompere il comportamento già esistente.
Questo è il punto che rende SWE-bench interessante. Non basta che la patch “sembri sensata”. Non basta che il modello spieghi bene cosa voleva fare. Non basta nemmeno che modifichi il file giusto.
Alla fine contano i test.
Naturalmente anche qui bisogna stare attenti: la qualità del benchmark dipende dalla qualità dei test. Se i test sono deboli, una patch può passare pur essendo concettualmente sbagliata. Se i test sono fragili o troppo legati all’ambiente, una patch corretta può fallire. Per questo l’esecuzione locale del benchmark non è soltanto “lancio un comando e leggo una percentuale”: richiede attenzione metodologica.
Quanti test, quante ripetizioni, quale score?
Una tentazione naturale sarebbe prendere i 731 task pubblici, lanciarli tutti una volta e leggere il risultato finale.
È un punto di partenza, ma non basta sempre.
Ci sono almeno quattro aspetti da considerare.
1. Il subset
Se uso tutti i 731 casi pubblici, ottengo un numero più stabile, ma spendo molto tempo.
Se uso 10, 20 o 50 casi, posso iterare più velocemente, ma il risultato è molto più rumoroso.
Per fare debugging dell’infrastruttura bastano pochi casi. Per confrontare seriamente quantizzazioni diverse serve un subset più ampio, e possibilmente scelto con criterio: linguaggi diversi, repository diversi, patch di dimensioni diverse, task facili e task difficili.
2. Le ripetizioni
I coding agent sono sistemi non deterministici. Anche a temperature bassa o zero possono esserci differenze dovute al backend, al parsing dei tool, al comportamento dell’agente, ai timeout e alla gestione dei comandi.
Una singola esecuzione può essere informativa, ma non racconta tutta la storia.
Per confronti seri avrebbe senso ripetere almeno alcuni task più volte, soprattutto se si vogliono confrontare modelli o quantizzazioni vicini tra loro.
3. Il tipo di fallimento
Uno score finale dice poco.
È molto più utile classificare i fallimenti:
- patch vuota;
- patch non applicabile;
- patch applicabile ma test falliti;
- timeout;
- errore nell’ambiente Docker;
- modello che modifica test o file non ammessi;
- agente che non riesce a interagire correttamente con il container;
- patch plausibile ma incompleta.
Nel mio primo esperimento locale, ad esempio, una patch generata da Qwen3.6 35B A3B quantizzato non ha passato il task, ma questo è comunque stato utile: la patch era non vuota, si applicava, i test partivano e arrivavano a un risultato concreto. Questo significa che la pipeline stava finalmente misurando qualcosa di reale.
4. Il tempo
La validazione di una patch è una cosa. Generare la patch con un agente locale è un’altra.
La validazione con Docker può richiedere decine di secondi o minuti per istanza. La generazione della patch, invece, può richiedere molto di più, soprattutto se il modello locale è lento, il task è lungo e l’agente fa molti passaggi.
Quindi un esperimento completo non si pianifica solo contando i task. Si pianifica anche stimando:
- tempo di generazione;
- tempo di validazione;
- spazio disco per immagini e output;
- parallelismo sostenibile;
- probabilità di timeout;
- costo di ripetere più run.
Perché eseguire SWE-bench Pro in locale
A questo punto uno potrebbe chiedersi: perché complicarsi la vita?
Se esistono leaderboard pubbliche, perché scaricare dataset, immagini Docker, agenti, modelli locali e mettersi a far girare tutto su una macchina consumer?
La risposta, nel mio caso, è semplice: perché le leaderboard non rispondono a tutte le domande pratiche.
A me interessa capire, ad esempio:
- un modello locale quantizzato a 4 bit perde molto rispetto a 6 o 8 bit?
- un MoE piccolo-attivo ma grande-totale si comporta meglio o peggio di un denso più piccolo?
- un modello più lento ma più accurato conviene davvero in un workflow agentico?
- quanto impatta la dimensione del contesto?
- quanto la quantizzazione della KV-cache?
- quali errori fa il modello quando fallisce?
- il problema è la qualità del modello o l’infrastruttura attorno?
Queste domande non si risolvono guardando un punteggio su Artificial Analysis o una tabella di benchmark pubblica.
Bisogna eseguire esperimenti controllati.
Nel mio caso il contesto è quello già discusso in altri post: un sistema basato su AMD Ryzen AI Max+ 395 (Strix Halo) con 128 GB di memoria unificata, usato per inferenza locale con modelli openweight.
È una macchina interessante perché permette di caricare modelli relativamente grandi, ma costringe anche a fare i conti con compromessi reali: quantizzazione, velocità di prefill, velocità di generazione, memoria, backend, contesto, tool call, stabilità.
SWE-bench Pro diventa quindi un modo per spostare la domanda da:
quanti token al secondo fa questo modello?
A:
questo modello, in questa configurazione, riesce davvero a portare a casa patch corrette su task realistici?
Sono due domande molto diverse.
Il percorso pratico: prima validare il verificatore
Una volta scaricato il progetto del benchmark da GitHub, la prima cosa che ho fatto non è stata generare patch con un modello locale.
Prima ho voluto verificare che il sistema di valutazione funzionasse.
Per farlo ho usato le gold patch, cioè le patch ufficiali associate alle istanze del benchmark. L’idea è semplice: se applico la patch corretta e l’evaluator non la riconosce come corretta, il problema non è il modello. È il benchmark setup.
Ho quindi preparato:
- il CSV con le istanze pubbliche;
- il JSON con le gold patch;
- subset piccoli da 1, 10 e poi 73 casi;
- l’esecuzione locale dell’evaluator con Docker.
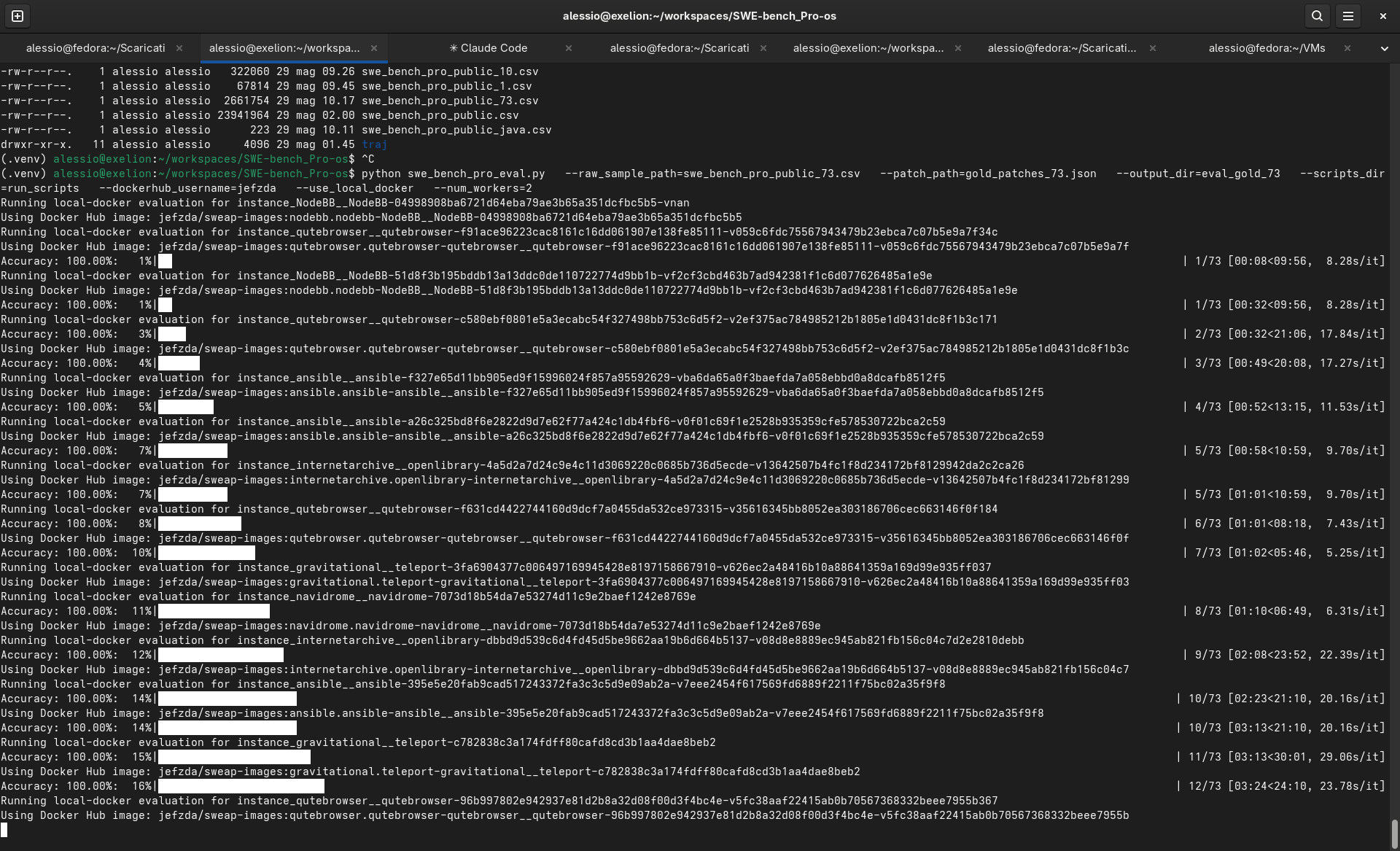
Questo passaggio è stato fondamentale, perché ha fatto emergere subito problemi locali legati a disponibilità di spazio disco assegnato alla macchina virtuale, permessi e SELinux.
Poi generare patch con un modello locale
Per generare patch ho usato mini-swe-agent, collegato a un modello locale esposto tramite API compatibile OpenAI.
Il modello del primo esperimento è stato Qwen3.6 35B A3B, quantizzato a 6 bit (KV-cache a 8 bit), servito localmente tramite LM Studio. Non è una scelta pensata per battere una leaderboard. È una scelta utile per iniziare a testare una pipeline locale con un modello openweight realistico per il mio hardware.
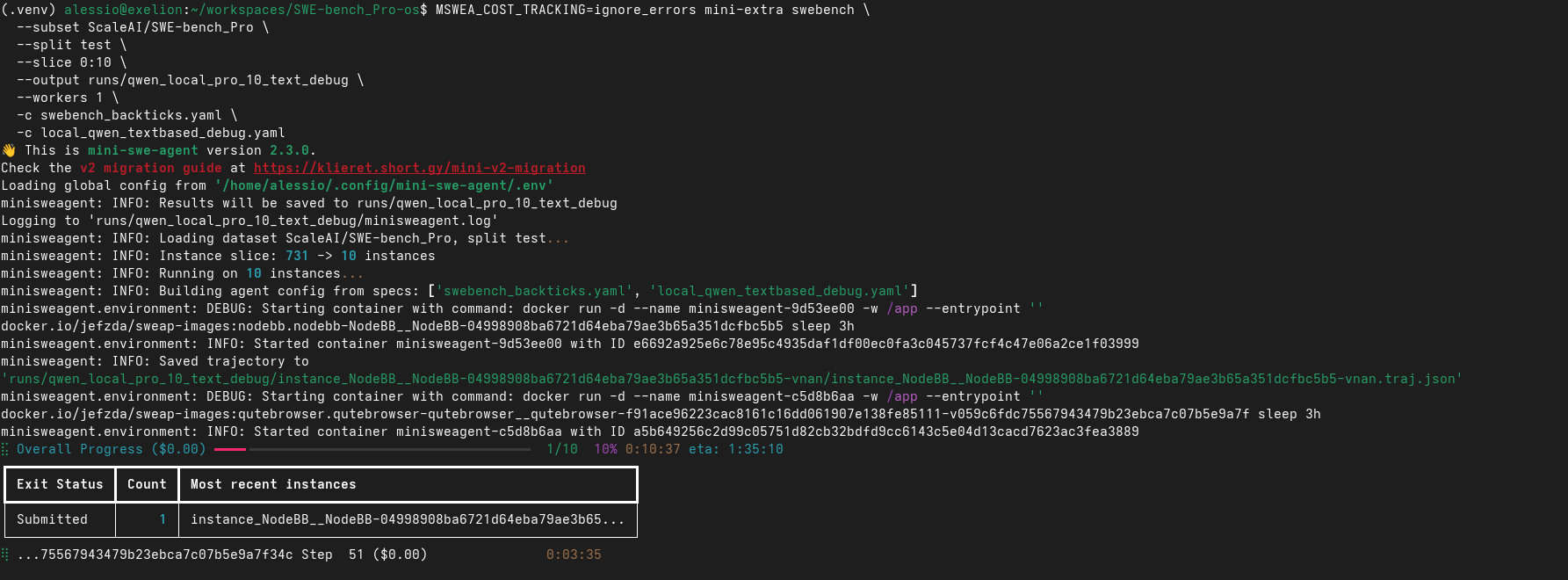
Anche qui, però, le cose non hanno funzionato al primo colpo e hanno richiesto migliorie allo script di esecuzione e file di configurazione per tool calling text-based, indicare il percorso corretto dove trovare le working directory nelle immagini Docker, …
Il primo risultato: una patch vera, ma non corretta
Dopo questi aggiustamenti, la pipeline ha prodotto finalmente una patch non vuota.
Questo, da solo, era già un risultato.
La patch è stata convertita nel formato atteso dall’evaluator SWE-bench Pro e validata con lo stesso meccanismo usato per le gold patch.
Il task scelto era un caso NodeBB relativo alla gestione dello stato di validazione email nell’Admin Control Panel e nella logica di conferma.
La patch generata dal modello non ha passato il benchmark.
E non è sorprendente.
Il punto interessante è che non ha fallito per un problema infrastrutturale. La patch si applicava, i test partivano, NodeBB veniva avviato, e la suite selezionata arrivava a un risultato concreto: 300 test eseguiti, 297 passati e 3 falliti.
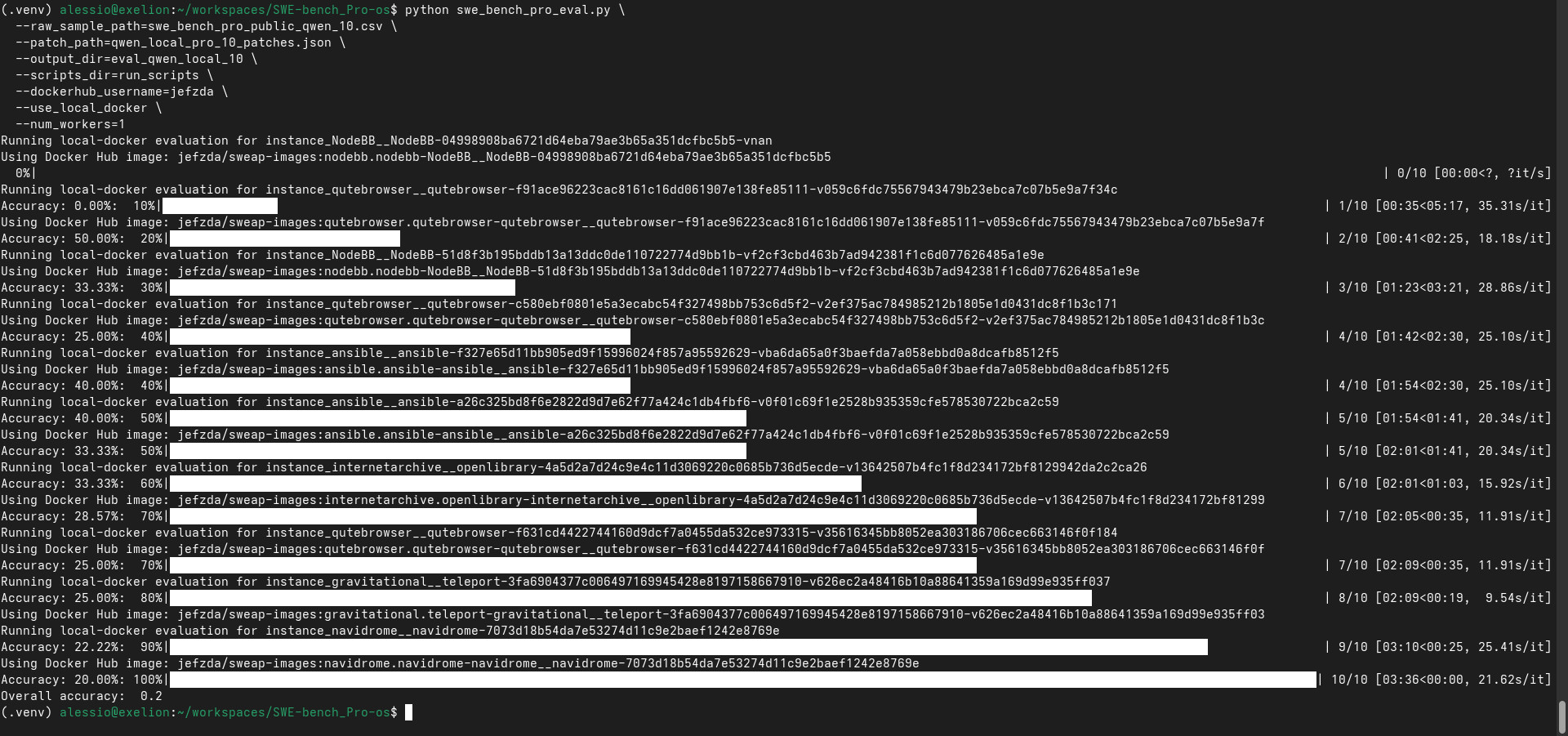
Questo è esattamente il tipo di fallimento utile.
Non “non funziona niente”.
Ma:
il modello ha prodotto una patch plausibile, applicabile, ma semanticamente incompleta o sbagliata.
Nel caso specifico, la modifica sembrava troppo locale e probabilmente non affrontava davvero il problema più ampio della validazione email e del fallback sui dati scaduti o mancanti.
Questo è il tipo di dato che voglio raccogliere nei prossimi esperimenti: non solo quanti task passano, ma come falliscono quelli che non passano.
Cosa ho imparato fin qui
Questa prima fase mi ha confermato alcune cose.
La prima: eseguire SWE-bench Pro in locale è possibile, ma non è un comando magico. Serve trattarlo come un vero sistema sperimentale.
La seconda: prima di misurare i modelli bisogna validare l’infrastruttura. Le gold patch sono indispensabili per capire se il verificatore funziona.
La terza: gli errori più fastidiosi non arrivano necessariamente dal modello. Possono arrivare da Docker, SELinux, entrypoint, working directory, immagini non adatte allo scaffold dell’agente, parser dei tool o limiti di spazio disco.
La quarta: un benchmark di coding agent non misura solo il modello. Misura l’intero sistema:
- modello;
- quantizzazione;
- backend di inferenza;
- prompt;
- agente;
- tool calling;
- container;
- test harness;
- timeout;
- parser dell’output;
- strategia di retry.
Questo rende i risultati più difficili da interpretare, ma anche molto più interessanti.
Perché questo conta per la quantizzazione
Il motivo per cui mi interessa davvero eseguire SWE-bench Pro in locale è la quantizzazione.
Quando si usano modelli openweight su hardware consumer, la quantizzazione non è un dettaglio tecnico. È spesso ciò che rende possibile o impossibile usare un certo modello.
Ma la domanda importante non è solo:
quanto è veloce Q4 rispetto a Q6?
La domanda è:
quanto perde Q4 in capacità agentica rispetto a Q6 o Q8?
Un modello quantizzato più aggressivamente può essere abbastanza buono in chat, ma fallire più spesso quando deve:
- mantenere coerenza su molti step;
- leggere output lunghi;
- produrre patch precise;
- evitare modifiche inutili;
- seguire istruzioni rigide;
- non perdersi nella logica di una codebase reale.
SWE-bench Pro permette di iniziare a misurare proprio questo.
Non perfettamente. Non senza rumore. Non senza problemi di contaminazione sul public set.
Ma in modo molto più concreto di un semplice confronto di token al secondo o di score sintetici.
Prossimi passi
Questo post non contiene ancora una tabella di risultati.
Volutamente.
Prima volevo raccontare il metodo, i problemi incontrati e il motivo per cui secondo me vale la pena fare questo tipo di esperimento.
I prossimi passi saranno:
- selezionare un subset più ragionato dei 731 task pubblici;
- classificare i task per linguaggio, repository e dimensione della gold patch;
- eseguire più modelli o più quantizzazioni con lo stesso scaffold;
- distinguere i fallimenti infrastrutturali dai fallimenti del modello;
- confrontare non solo il pass rate, ma anche i tipi di errore.
Solo a quel punto avrà senso parlare di numeri.
Per ora il risultato è più modesto, ma importante: la pipeline locale funziona. Il modello locale produce patch. L’evaluator le valida. E i fallimenti iniziano a essere informativi.
Per il resto… servirà tempo ;-)