
L’intelligenza artificiale non si limita più a riconoscere oggetti generici come “persona” o “auto”. Con Gemini 2.5, possiamo descrivere scenari complessi in linguaggio naturale e ottenere risposte visive su misura. Ecco due esempi pratici di come può essere utile nella vita reale.
🧠 Cos’è la segmentazione conversazionale?
La segmentazione conversazionale permette di selezionare solo ciò che ci interessa in un’immagine, usando descrizioni naturali come:
- “oggetti che potrebbero causare danni al tagliaerba automatico”
- “aree danneggiate visibili nella scena”
- “oggetti sul prato, ma non su quello sintetico”
Il sistema risponde evidenziando le porzioni esatte dell’immagine, andando ben oltre i classici “bounding box” rettangolari.
💡 Caso d’uso 1 – Identificazione di un rischio elettrico
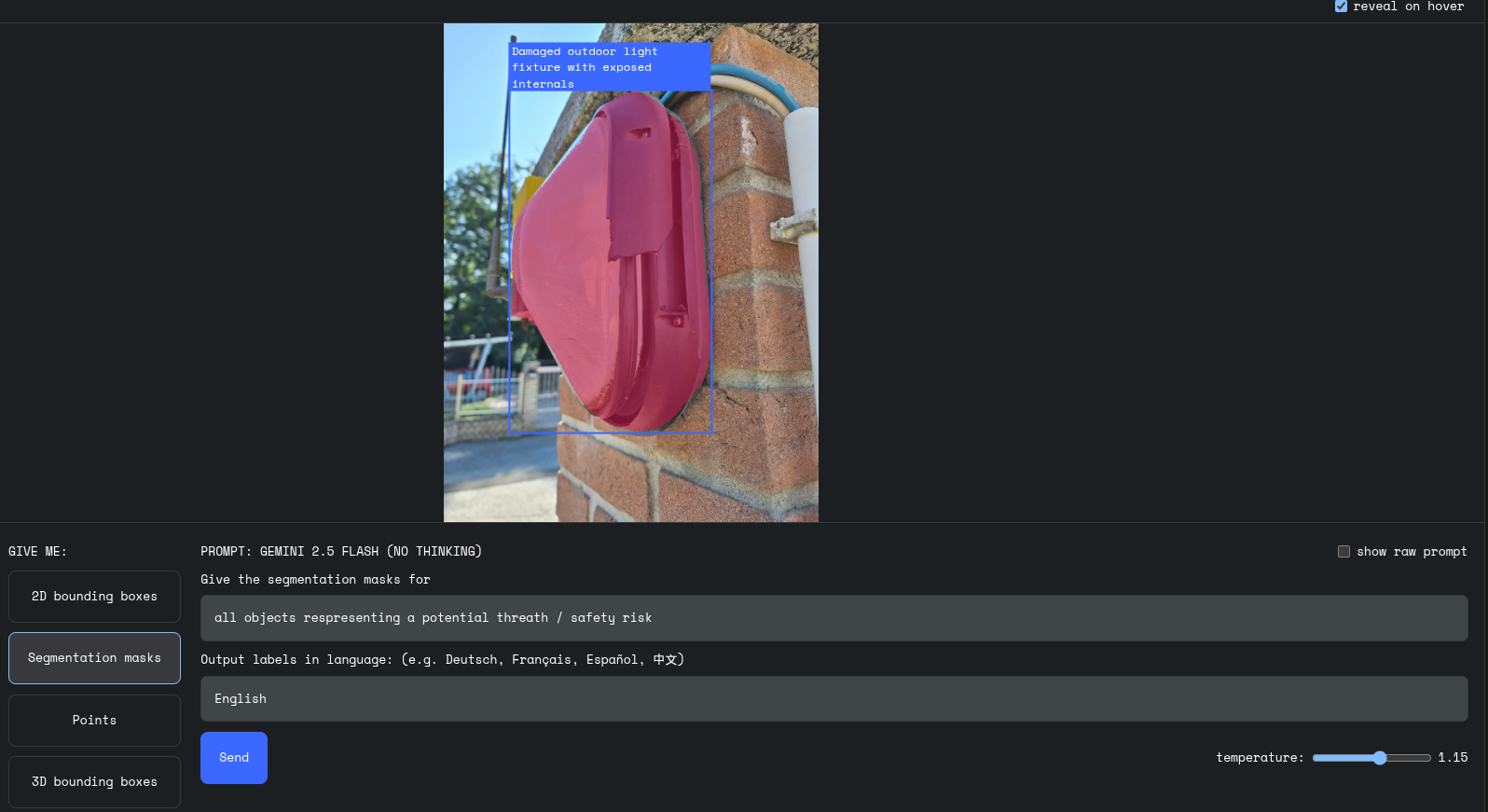
In questa immagine, la richiesta al modello è:
“Mostrami gli oggetti che rappresentano una minaccia per la sicurezza.”
Il modello evidenzia una plafoniera danneggiata con cablaggi esposti, potenzialmente pericolosa in caso di pioggia. Questo tipo di analisi può essere automatizzato in ambito sicurezza, manutenzione o ispezione remota di impianti.
🌱 Caso d’uso 2 – Preparazione automatica del giardino prima del taglio
Contesto:
Un sistema di sorveglianza monitora il giardino. Prima che parta il tagliaerba automatico, vogliamo sapere se ci sono oggetti lasciati sull’erba che potrebbero essere danneggiati o incastrarsi nelle lame.
📸 Immagine 1 – Situazione iniziale
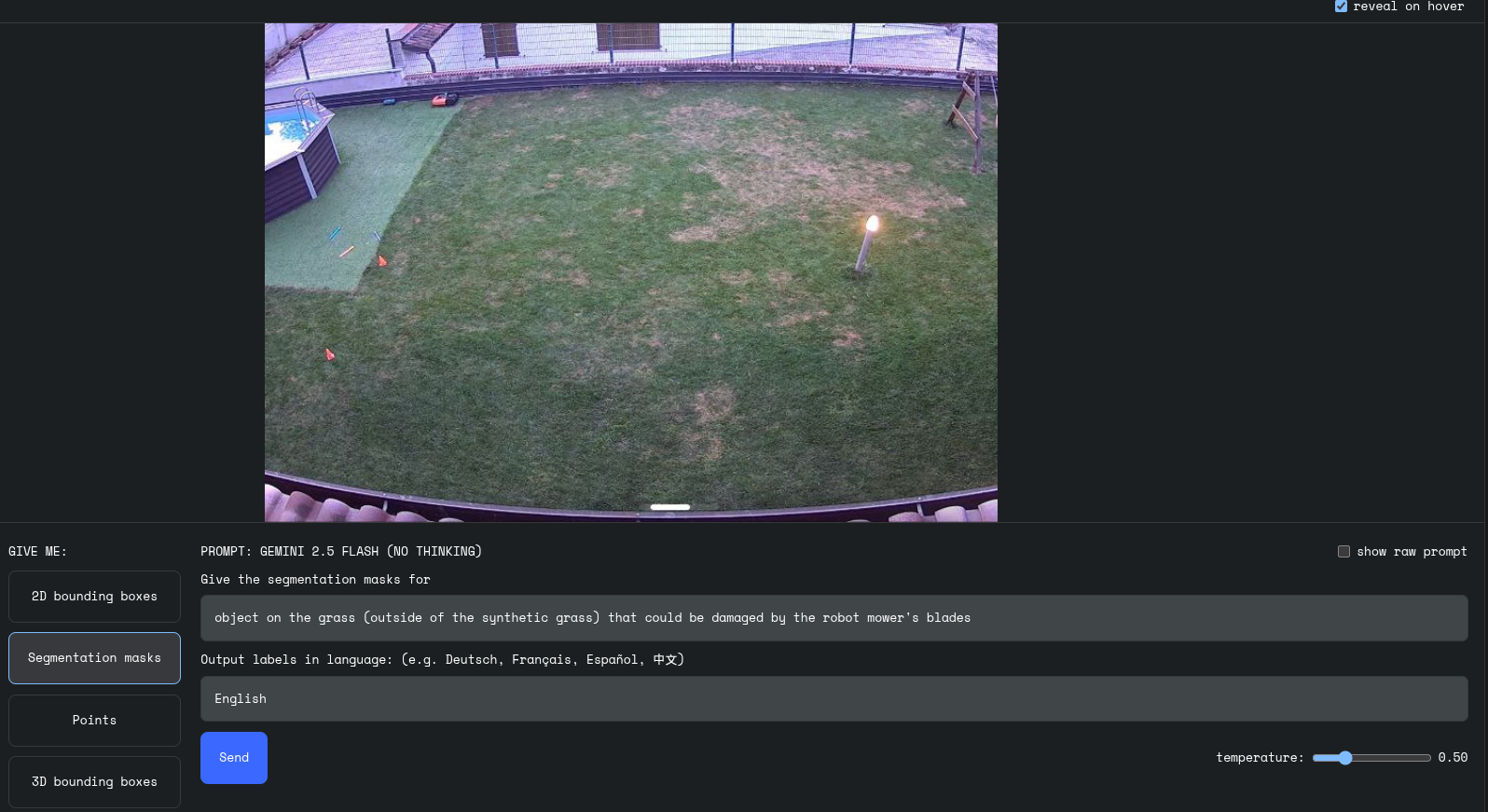
Prompt dato al modello:
“Segnala oggetti sull’erba (escludendo l’erba sintetica) che potrebbero essere danneggiati dalle lame del tagliaerba.”
✅ Risultato del modello
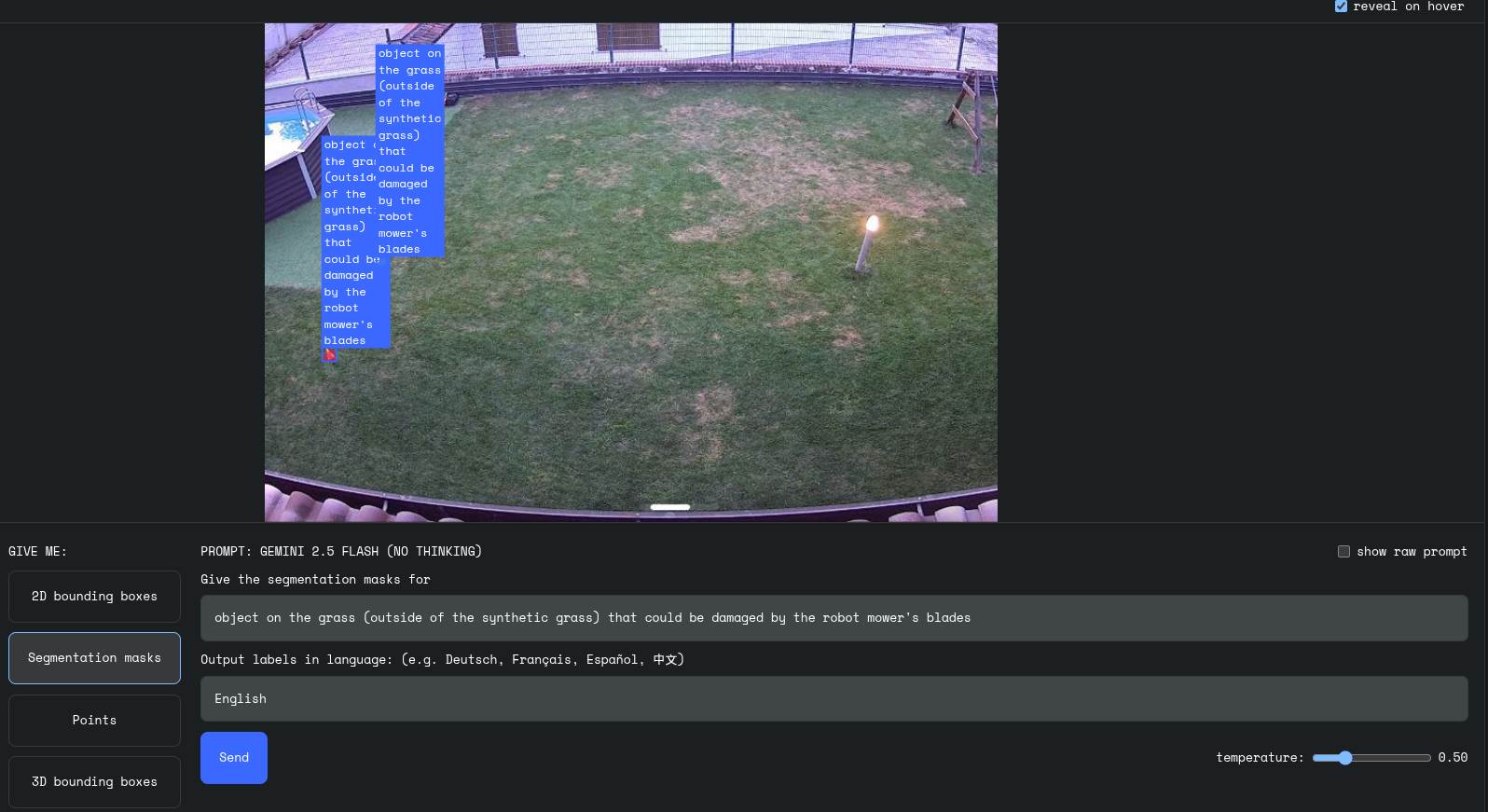
Notare come:
- Gli oggetti sul prato sintetico (area in alto a sinistra) vengono ignorati
- Gli oggetti troppo grandi (come il palo con luce a destra) non vengono segnalati, perché non rappresentano una minaccia per le lame
- Vengono invece individuati i piccoli coni in plastica arancione sul prato, potenzialmente dannosi (e danneggiabili…) se raggiunti dal robot
Questa logica permette di attivare notifiche automatiche all’utente, migliorando sicurezza ed efficienza del sistema.
🚀 Conclusioni
La segmentazione conversazionale di Gemini 2.5 trasforma un’immagine in un’interfaccia interattiva: basta una frase, e l’IA risponde visivamente. Con applicazioni che spaziano dalla sicurezza alla domotica, questo tipo di intelligenza visiva apre scenari molto concreti anche per sviluppatori e maker.