Attraverso la combinazione di una serie di desideri (prompt)
Oggi vediamo come Aladino possa istruire il genio per creare una finzione dall’impatto visivo molto potente.
Per chi non dispone della propria preziosa lampada magica (leggasi: un computer con potente GPU e sufficiente memoria grafica), la lampada necessaria è facilmente noleggiabile online per poche decine di euro al mese, comprensiva di un numero limitato ma più che sufficiente di desideri esprimibili.
Ora, si dà il caso che il logo del blog — ancorché carino — non sia una perla di design. Il blog stesso, men che meno.
Quindi “Aladino Digitale” ha deciso di aprire una posizione lavorativa per un giovane designer alternativo, che porti idee fresche e anticonvenzionali.
Abbiamo svolto già un paio di colloqui, ma qualcosa mi dice che Giulia, la prossima candidata, abbia il carattere che cerchiamo…



Ma chi è Giulia? Da dove viene?
Il panorama della generazione immagine
Il panorama attuale dei modelli di generazione immagine utilizzabili offline (Stable Diffusion, Flux, …) e online (DALL·E, Imagen, …) offre molteplici soluzioni per creare immagini a partire da testo, sotto forma di parole chiave o vere e proprie descrizioni.
A mio avviso, se l’obiettivo è ottenere immagini di persone il più foto-realistiche possibile, il generatore di immagini di Gemini (Imagen) è la soluzione migliore.
Risparmiate ore di test con le alternative: non resta che cominciare. Ma cosa chiediamo a Gemini?
La formulazione del desiderio (prompting)
Sebbene molti siano in grado di esprimersi correttamente in inglese, la creazione dei prompt è una di quelle attività in cui essere madrelingua fa davvero la differenza. Per fortuna, esiste una nuova magia per formulare le istruzioni: ChatGPT, utilizzabile gratuitamente per alcune richieste giornaliere, oppure con sottoscrizione a circa 23€/mese.
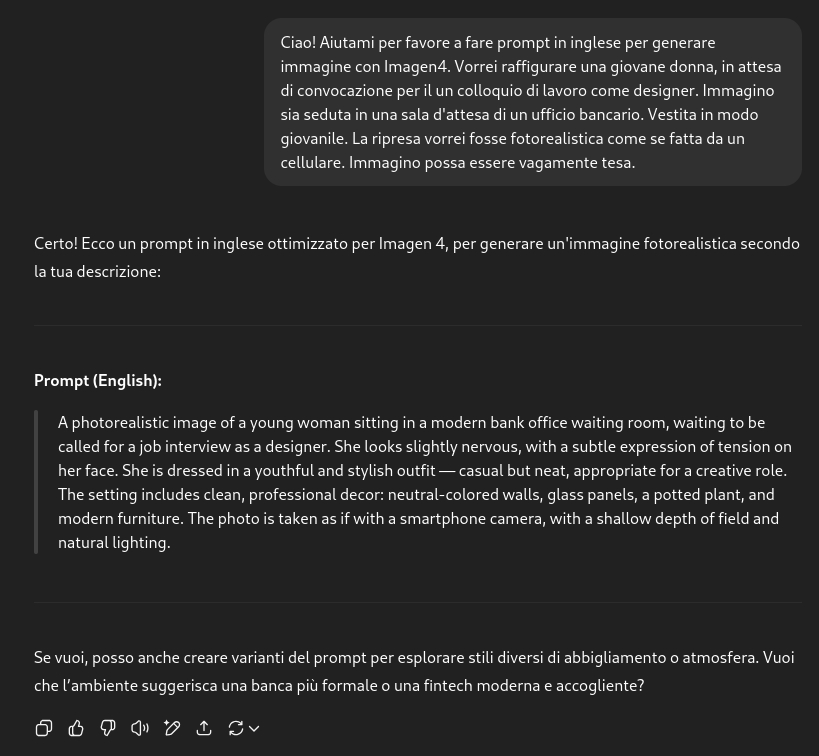
Primo tentativo: Gemini
OK, abbiamo un bel prompt. Lo passiamo a Gemini…
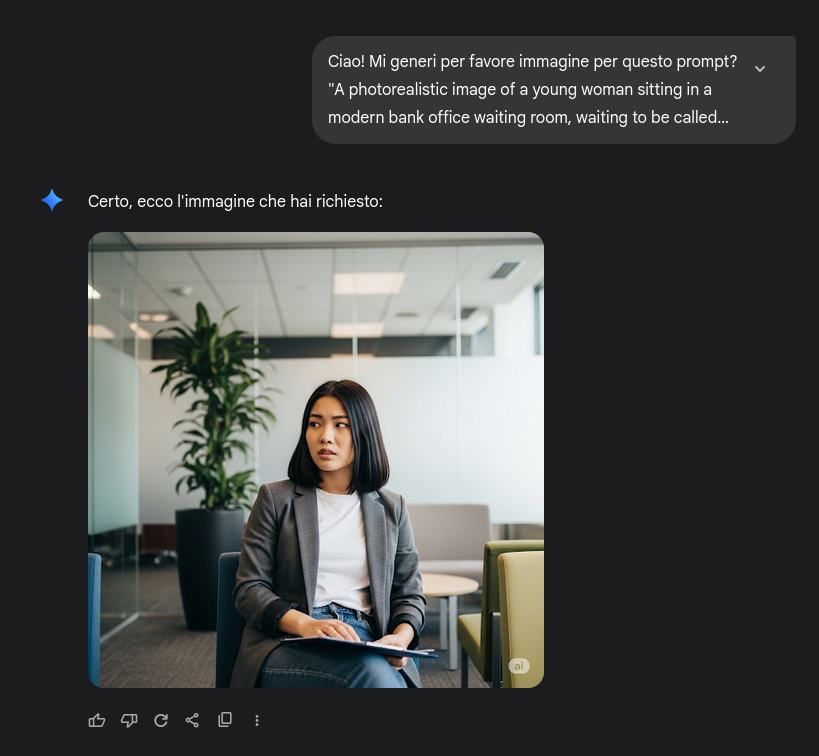
…ehm, non esattamente il risultato sperato. Aladino Digitale cerca candidati in Italia, tanto per cominciare. Continuiamo la conversazione con ChatGPT…
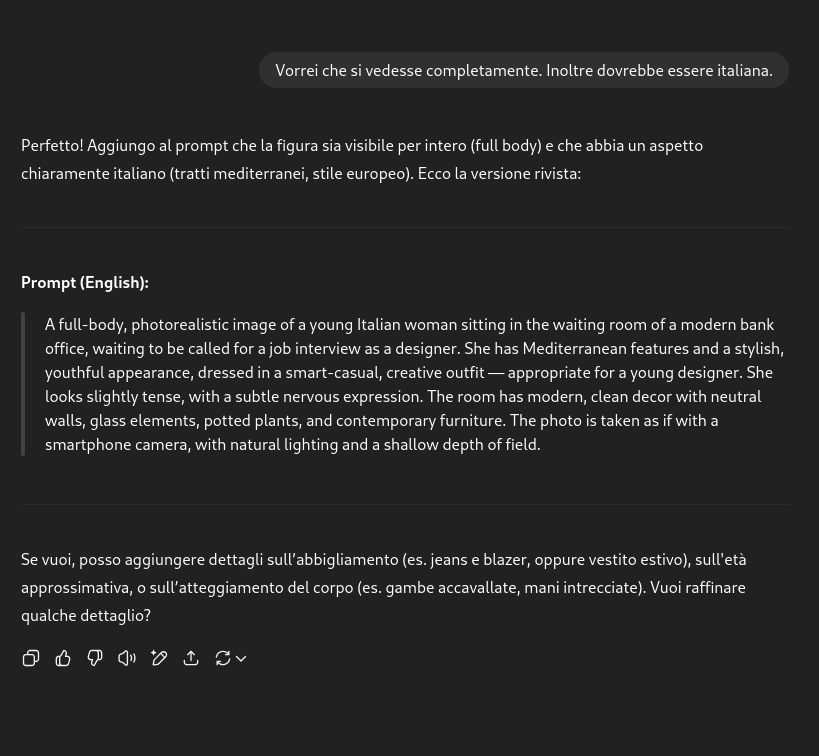
…e chiediamo nuovamente a Gemini di convertire il prompt in immagine:
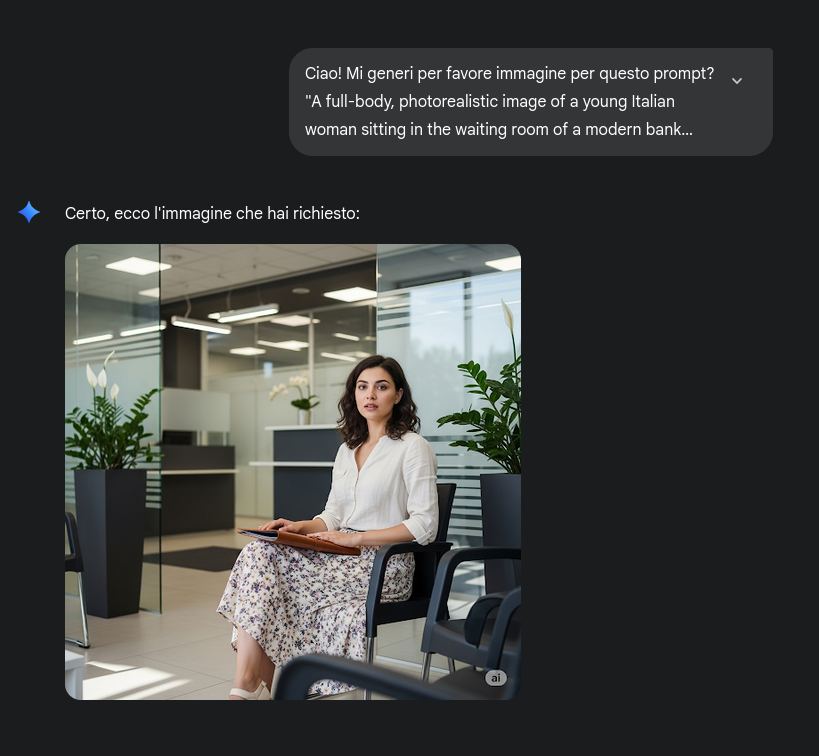
Meglio! Ma ci sono ancora due o tre aspetti da sistemare: abbigliamento, accessori (collana, bracciali, etc.), posa del soggetto, composizione dell’immagine, ambientazione presso gli uffici di Aladino Digitale…
Iterazioni: migliorare il risultato
Proseguiamo generando ulteriori immagini con Gemini, spiegando a ChatGPT le modifiche desiderate. In effetti potremmo usare solo Gemini sia per il prompting che per la generazione, dato che i costi sono simili.
La “lampada magica” non genera sempre la stessa immagine per lo stesso prompt e spesso il risultato non è perfettamente coerente, consistente o esteticamente piacevole. Fintanto che l’immagine è plausibile, vale comunque la pena tenerla da parte: potrebbe tornarci utile più avanti.
Dopo un certo numero di iterazioni (a seconda di quanto siamo pignoli), ecco finalmente la nostra eccentrica designer alternativa: Giulia.
Rimozione del watermark
Le immagini generate da Gemini hanno un watermark visibile (“ai”) nell’angolo in basso a destra. Per questa dimostrazione, rimuoveremo il watermark — operazione facilmente realizzabile con un qualsiasi editor d’immagini, ad esempio tramite riquadratura.
È comunque importante che le immagini generate da AI siano marchiate come tali. Oltre al watermark visibile, Gemini inserisce anche un watermark nascosto nei bit dell’immagine, molto più difficile da rimuovere. Ma su questo aspetto torneremo in un altro post.
Generare variazioni: primi piani di Giulia
Ora vogliamo generare due ulteriori immagini in primo piano. Nota: le due immagini non sono semplici ritagli della foto originale di Giulia seduta — l’inquadratura, l’apertura degli occhi e la posa sono leggermente differenti.
Ci serviamo di una nuova lampada magica: OpenArt.ai. A partire da 14 USD/mese, offre un ventaglio enorme di strumenti per generazione, editing intelligente, creazione di video e molto altro.
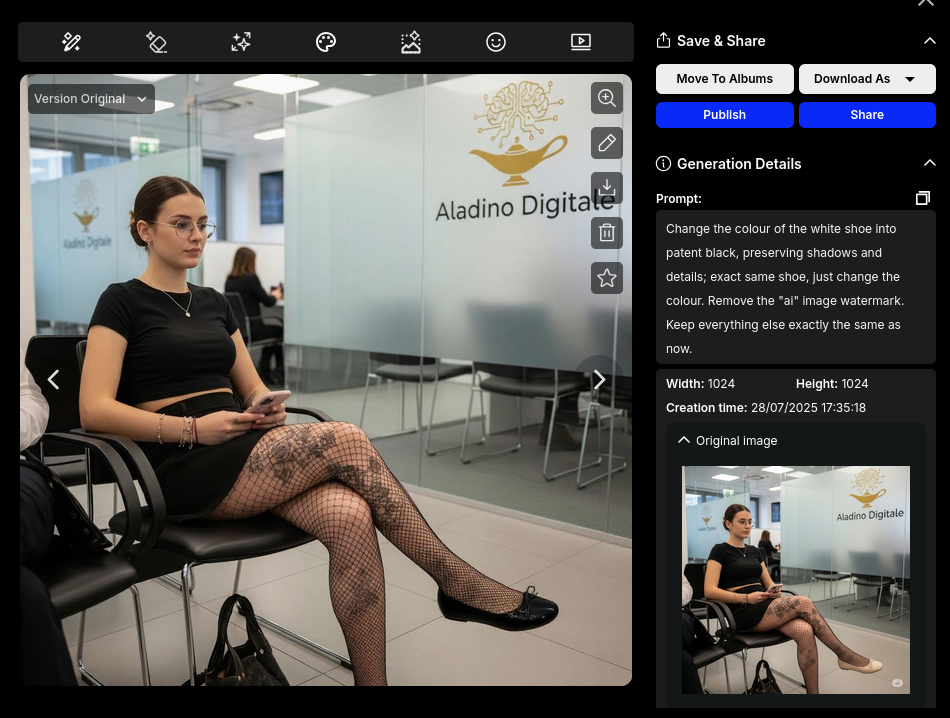
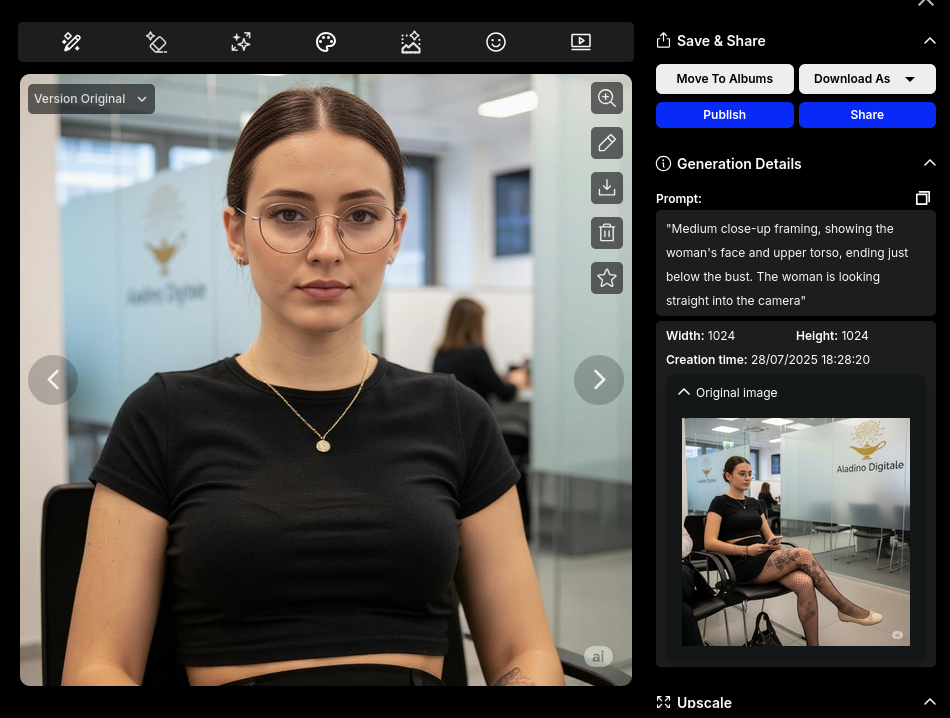
Editing intelligente con Flux Kontext Max
OpenArt fornisce varie modalità per il ritocco delle immagini. Le immagini qui sopra sono state ottenute usando la modalità “Chat”, che permette all’utente di descrivere in linguaggio naturale le modifiche desiderate.
Anche in questo caso ci può aiutare ChatGPT, scrivendo un prompt conciso, adatto al modello AI selezionato in OpenArt. Noi abbiamo scelto Flux Kontext Max, particolarmente efficace per la trasformazione di soggetti umani.
Una volta soddisfatti del risultato, OpenArt permette anche di eseguire l’upscaling delle immagini a risoluzioni superiori.
Riflessioni
Perché questo post?
A parte il divertimento nel giocare con i tool descritti sopra, l’intenzione è duplice:
- Mostrare cosa si possa ottenere senza competenze specifiche o risorse eccessive — bastano un paio di decine di Euro.
- Far riflettere sui potenziali inganni dietro molti dei contenuti visivi che circolano online.
Il procedimento descritto qui è piuttosto naive, ma già esistono strumenti più evoluti per la creazione di personaggi virtuali e per produzioni deep fake.
Ora Giulia va al suo colloquio… noi ci rivediamo presto con nuovi sviluppi.