
🧭 Come orientarsi tra i modelli AI da usare in locale
Un vademecum pratico tra formati, quantizzazioni e risorse
1. Introduzione: perché serve una bussola
Nel mondo della AI generativa open-source oggi esistono migliaia di modelli scaricabili: linguistici, visivi, audio e multimodali.
Al netto del nome generico del modello — LLaMA, Mistral, Flux, Stable Diffusion XL, Gemma — esistono spesso varianti con suffissi simili, ma dietro quei nomi si nascondono differenze sostanziali in termini di architettura, peso e compatibilità.
Il risultato? È facile scaricare un modello che non si carica in memoria, o che funziona ma produce risultati scadenti perché non è del tipo giusto (ad esempio, un modello base usato in chat).
Questo post vuole essere una guida operativa per capire:
- dove trovare i modelli affidabili,
- come leggere nomi e formati,
- cosa significano le sigle (FP16, Q4_K, GGUF, ecc.),
- e come scegliere in base all’hardware che si ha a disposizione.
2. Dove si trovano (e come si usano) i modelli
Oggi i modelli open weight si trovano su alcune piattaforme che ne facilitano la distribuzione e l’esecuzione in locale.
Tra le principali si segnalano:
| Piattaforma | Tipo di modelli | Note |
|---|---|---|
| 🧠 Hugging Face Hub | LLM, visione, audio, multimodali | repository universale e standard de facto per modelli open-source |
| ⚙️ Ollama Library | LLM pronti all’uso in formato GGUF | download e installazione automatica tramite CLI |
| 🎨 CivitAI | modelli visivi (Stable Diffusion, LoRA, ControlNet) | forte componente community e rating degli utenti |
| 💻 LM Studio | LLM in formato GGUF | permette di cercare, scaricare e avviare modelli direttamente dall’interfaccia grafica |
💡 In breve:
- Hugging Face è la fonte “universale” per modelli e dataset.
- Ollama e LM Studio sono i modi più semplici per scaricare e usare subito un LLM in locale, con setup minimo.
- CivitAI è la community di riferimento per Stable Diffusion e i modelli visivi.
Altri tool per eseguire modelli localmente
Oltre a Ollama e LM Studio, esistono molti altri strumenti, spesso più specializzati o sperimentali.
🔤 Per modelli linguistici (LLM)
- Ramalama.ai — alternativa leggera e open-source per gestire modelli GGUF con UI minimale.
- KoboldCPP, Jan, TGI — opzioni CLI o server REST per inferenza locale e self-hosted.
🖼️ Per modelli di immagini
- ComfyUI — ambiente visuale modulare, ideale per workflow complessi e composizioni.
- Automatic1111 WebUI — l’interfaccia più diffusa per Stable Diffusion, con ampia disponibilità di estensioni.
💡 Questi strumenti non ospitano i modelli, ma li scaricano automaticamente da repository come Hugging Face o CivitAI (o li leggono da disco a seguito di download manuale), e ne gestiscono il caricamento, la quantizzazione e i parametri di inferenza.
3. Capire il tipo di modello
3.1. Base vs Instruct
I modelli base vengono addestrati a prevedere il token successivo in un testo — ottimi per completamento o analisi, ma poco reattivi a istruzioni umane.
I modelli Instruct, invece, sono “fine-tuned” per rispondere a comandi naturali, tipo “scrivi un’email” o “spiega questo codice”.
Esempio:
Mistral 7B→ base model (buono per completamento).Mistral 7B Instruct→ adatto a chat e prompting naturale.
Oggi quasi tutti i modelli distribuiti al pubblico (LLaMA 3, Gemma, Phi-3, ecc.) hanno una variante Instruct. È quella che ti serve nel 90% dei casi.
3.2. Distilled, Merged, Adapter
Un modello può derivare da un altro tramite tecniche di “compressione” o specializzazione:
- Distilled: riduzione dei parametri tramite “insegnamento” da un modello più grande (es. LLaMA-3.1 70B distilled → 8B).
- Merged: fusione di più modelli per combinare stili o competenze.
- Adapter / LoRA: estensioni leggere (pochi MB) che modificano il comportamento, tipiche nel mondo Stable Diffusion ma sempre più diffuse anche nei LLM (es. per coding o personaggi roleplay).
💡 LoRA e Adapter permettono di cambiare “personalità” o competenza del modello senza riscaricarlo completamente.
4. Formati di modello e compatibilità
A seconda di come è stato esportato, un modello può trovarsi in formati diversi.
Ecco i principali e come si usano:
| Formato | Tipico uso | Tool compatibili | Note |
|---|---|---|---|
| GGUF / GGML | LLM quantizzati | Ollama, LM Studio, llama.cpp | formato leggero, ottimizzato per inferenza su CPU o GPU consumer |
| Safetensors | Stable Diffusion, PyTorch | ComfyUI, SD WebUI, diffusers | formato binario sicuro e rapido, sostituisce i vecchi .ckpt |
| FP16 / FP32 checkpoint | addestramento o inferenza di alta qualità | PyTorch, HF Transformers | full precision, adatti a GPU con molta VRAM |
| ONNX | interoperabilità | ComfyUI, OpenVINO, DirectML, TensorRT | esecuzione cross-framework, utile per porting e deployment |
| TensorRT / CoreML / TFLite | inferenza ottimizzata | NVIDIA, Apple, Android | conversioni mirate per acceleratori dedicati |
🧩 ONNX in breve:
È un formato neutro pensato per spostare modelli tra framework (PyTorch, TensorFlow, etc.) e sfruttare motori ottimizzati come TensorRT o DirectML.
In ambito LLM, però, non è ancora lo standard dominante: le implementazioni personalizzate rendono difficile la conversione di modelli complessi.
5. La quantizzazione spiegata semplice
La quantizzazione è la tecnica che consente di ridurre la dimensione di un modello convertendo numeri a 32-bit (FP32) in rappresentazioni più compatte: 16-bit, 8-bit o anche 4-bit.
In pratica, si riduce la precisione numerica per risparmiare memoria, con una perdita minima di qualità.
5.1. Cosa significano Q4, Q6_K, Q8_M…
Ogni file .gguf o .ggml porta con sé una sigla che descrive come i pesi sono stati compressi:
| Sigla | Significato | Trade-off |
|---|---|---|
| Q4_0 / Q4_1 | quantizzazione 4-bit semplice | leggero ma riduce la coerenza linguistica |
| Q4_K / Q6_K | K-block quantization | bilanciato, oggi lo standard per uso generale |
| Q8_M | mixed-block quantization | quasi indistinguibile dal full precision |
🔍 Le lettere K e M indicano la strategia di blocco e statistiche usate per comprimere i pesi.
Le versioni con K (comeQ6_K) sono le più stabili; le M spesso derivano da schemi misti più recenti.
5.2. FP16, FP32, INT8 — non solo memoria
La precisione non incide solo sul peso del file, ma anche sul modo in cui il modello viene eseguito dall’hardware.
| Precisione | Tipo dati | Supporto hardware | Uso consigliato |
|---|---|---|---|
| FP32 | floating point 32-bit | tutte le GPU/CPU | addestramento e benchmark |
| FP16 / BF16 | half precision | GPU moderne (RTX, RDNA3, M-series) | inferenza rapida ad alta fedeltà |
| INT8 / Q8 | intero 8-bit | CPU e NPU recenti | inferenza efficiente e mobile |
| Q4_K / Q6_K | quantizzato 4–6 bit | CPU o GPU limitate | ottimo compromesso locale |
⚙️ Esempio pratico:
UnMistral 7B FP16pesa ~14 GB e gira bene solo su GPU da 16 GB.
La versioneQ4_K_Mscende a 4.5 GB, eseguibile su CPU Ryzen o GPU da 6–8 GB, con una differenza minima nella qualità del testo.
5.3. Quando ha senso quantizzare
Ha senso quando:
- vuoi usare modelli grandi su hardware domestico;
- vuoi ridurre tempi di caricamento e consumi;
- lavori su laptop o mini-PC.
6. Checkpoint, merge e versioni
Ogni modello è un checkpoint — una “fotografia” dei pesi in un momento preciso dell’addestramento.
Su questa base nascono varianti:
- original release: modello ufficiale.
- fine-tuned: adattato a un dominio (coding, reasoning, conversazione).
- merged: fusione di più checkpoint o LoRA.
- LoRA standalone: piccole estensioni (da pochi MB) che modificano il comportamento del modello di base.
Esempio per Stable Diffusion:
realisticVisionV6.1_fp16.safetensors → versione 6.1, formato safetensors, precisione FP16.
7. Mixture of Experts (MoE): più cervelli, meno memoria?
I modelli Mixture of Experts (MoE) usano un principio semplice ma potente:
invece di avere un’unica rete neurale densa che elabora tutto, ne hanno più “esperti” specializzati (sub-reti), e a ogni token solo alcuni di essi vengono attivati.
In pratica:
- Il modello possiede molti più parametri complessivi, ma non li usa tutti contemporaneamente.
- Un meccanismo di routing decide quali esperti attivare per ogni token, in base al contesto.
- Questo permette di combinare capacità di ragionamento elevate con costi di memoria ridotti in fase di inferenza.
💡 Esempio intuitivo: immagina una squadra di specialisti: un linguista, un programmatore, un matematico.
Per una frase tecnica, il router chiama il programmatore e il linguista, lasciando “a riposo” gli altri.
Il modello resta veloce, ma conserva la conoscenza complessiva dell’intera squadra.
⚙️ Cosa comporta dal punto di vista tecnico
- Parametri totali: possono essere anche 100–200 miliardi, ma durante l’inferenza ne vengono usati solo 10–20%.
- Memoria richiesta: dipende dagli esperti attivi, non da quelli totali → di solito inferiore rispetto a un modello dense equivalente.
- Routing: può essere statico (stesso gruppo di esperti per ogni token) o dinamico (scelti in base al contesto, come nei modelli moderni).
📊 Prestazioni e compromessi
- Un MoE non è sempre più veloce: il routing introduce un piccolo overhead computazionale.
- Tuttavia, a parità di VRAM disponibile, può fornire risultati migliori rispetto a un modello denso di pari dimensioni “attiva”.
- In termini di qualità, un buon MoE da 20B con 2 esperti attivi può avvicinarsi a un dense da 70B, ma non lo eguaglia sempre: la performance dipende da quanto bene gli esperti sono addestrati e bilanciati.
7bis. Memoria del modello e memoria del contesto
Quando si parla di “memoria”, non si intende solo quella occupata dai pesi.
Ci sono due componenti distinte:
| Tipo di memoria | Cosa contiene | Dipende da | Impatto pratico |
|---|---|---|---|
| Model memory | i pesi del modello | architettura, quantizzazione | determina se il modello si carica |
| Context memory | la cache key/value dei token | lunghezza finestra (8K, 128K, 1M) | determina quanto testo può “ricordare” |
Esempio pratico:
Mistral 7B Q4_K_M: circa 6 GB per i pesi.- Finestra da 128K token: +8–12 GB per la cache del contesto.
💡 Un modello può “entrare in memoria”, ma non “ricordare” conversazioni lunghe se non ha spazio per la cache.
I tool come Ollama, LM Studio o llama.cpp permettono di regolare manualmente--ctx-sizeper bilanciare profondità e prestazioni.
8. Come valutare cosa scaricare (senza impazzire ogni settimana)
Il panorama dei modelli cambia continuamente: ogni mese compaiono nuove versioni, merge, quantizzazioni e fine-tuning.
Più che dare una lista di “modelli consigliati”, è utile capire come stimare in anticipo se un modello è compatibile con il proprio hardware.
🔢 8.1. Calcolare la memoria necessaria
Esistono diversi tool online e locali che permettono di stimare il consumo di memoria in base a:
- numero di parametri (es. 7B, 13B, 70B),
- precisione o quantizzazione (FP16, Q6_K, Q4_K, ecc.),
- dimensione del contesto (
--ctx-size).
Alcuni esempi:
💡 Esempio pratico: un modello da 7B parametri in FP16 occupa circa 14 GB, ma la versione
Q4_K_Mscende a ~4.5 GB — quasi un terzo — chiaramente con una certa perdita di qualità.
🧮 8.2. Filtrare i modelli per hardware su Hugging Face
Hugging Face oggi consente di filtrare i modelli per compatibilità hardware:
per alcune collezioni di modelli (ad esempio, suggerisco quella di Unsloth AI) si può specificare GPU o RAM disponibili e vedere quali modelli si riescono effettivamente a caricare.
Nell’immagine qui sotto vediamo quali versioni di gpt-oss-20b-GGUF è possibile utilizzare con una NVIDIA RTX 4090 Laptop version da 16GB di VRAM:
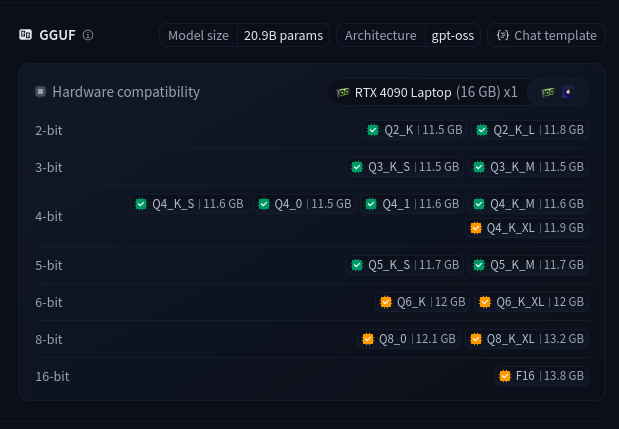
Questa funzione è utile per capire subito se un modello “entra” nella propria macchina senza doverlo scaricare a mano.
9. Sicurezza e provenienza
Scaricare un modello non è sempre sicuro:
- Evita modelli anonimi o “modificati” senza descrizione su CivitAI.
- Su Hugging Face controlla la model card: indica licenza, dataset e note etiche.
- Verifica l’hash SHA-256 se scarichi file
.ggufo.safetensorsmanualmente.
🚫 Attenzione ai file
.ckpt: alcuni possono contenere codice Python eseguibile. Preferisci sempre i.safetensors.
10. Conclusioni
Non esiste un “miglior modello universale”.
La scelta dipende da cosa vuoi fare, quanto puoi spendere in risorse e che livello di controllo ti serve.