
Eseguire modelli AI in locale (o in ambienti controllati): libertà, limiti e prospettive
Mentre le news di nuovi servizi e funzionalità di Gemini, Claude, ChatGPT, etc. si susseguono, permane un certo interesse nella community a proposito di soluzioni per eseguire modelli di intelligenza artificiale generativa fuori dai grandi servizi cloud. L’obbiettivo in sostanza è far girare modelli open-weight – cioè con pesi pubblicamente scaricabili – sul proprio computer o in ambienti cloud “controllati”, dove si sceglie quale modello usare, con quali dati e con quali vincoli.
Ma perché dovremmo volerlo fare?
Perché scegliere un ambiente controllato
L’uso di servizi gestiti (come ChatGPT o Gemini) offre comodità e prestazioni, ma comporta anche limiti importanti:
- Controllo dei dati – i prompt, i file caricati e i risultati possono transitare su infrastrutture esterne, con implicazioni per la privacy o la proprietà intellettuale.
- Dipendenza dal provider – le API possono cambiare, i modelli essere aggiornati o rimossi senza preavviso.
- Costi e scalabilità – per usi intensivi o sperimentali, le tariffe possono diventare elevate.
- Limitazioni operative – molti servizi impongono limiti di contesto o non permettono l’esecuzione di modelli personalizzati.
Ecco perché si registra l’interesse per soluzioni “local-first”: esecuzione in locale o in ambienti controllati, cioè cloud indipendenti o container privati dove si gestisce interamente l’infrastruttura e i modelli.
Local vs. ambiente controllato: cosa significa davvero
Parlare di “locale” non vuol dire per forza “sul proprio portatile / desktop”. Esistono oggi due grandi categorie:
- Esecuzione locale – tutto avviene sul proprio hardware, tipicamente con GPU o NPU dedicate.
- Esecuzione in ambienti controllati – si usano risorse cloud, ma mantenendo pieno controllo su modelli, codice e dati.
Alcuni servizi noti per quest’ultimo approccio:
- RunPod e TensorDock – ambienti GPU “pay-per-minute” per LLM e Stable Diffusion, con possibilità di personalizzare container e storage.
- RunComfy – piattaforma pronta per flussi ComfyUI, utile per generazione di immagini e video.
- Vast.ai e Lambda Cloud – soluzioni per affittare GPU a breve termine, con immagini preconfigurate per PyTorch, Diffusers e llama.cpp.
Queste opzioni offrono un buon equilibrio tra libertà e semplicità: il modello gira su macchine “tue” (o quasi), ma non devi preoccuparti di raffreddamento, alimentazione o driver.
I limiti: prestazioni, qualità, contesto
Naturalmente, eseguire in locale o in ambienti controllati non è gratis — in termini di potenza e maturità del software:
- Velocità: un LLM da 70–120B può raggiungere solo pochi token/s su GPU consumer.
- Qualità: i modelli open-weight più accessibili (Mistral, LLaMA, Gemma, Qwen, Flux) tipicamente non eguagliano GPT-4 o Gemini 2.5.
- Contesto limitato: 4k–32k token tipici, contro i 128k–1M dei modelli gestiti.
- Concorrenza: in un setup locale si può gestire solo un numero ridotto di richieste contemporanee.
Per questo, l’uso locale si presta bene a:
- prototipazione e ricerca,
- automazioni personali,
- sperimentazione su dati sensibili,
- edge computing o applicazioni offline.
A livello enterprise, invece, gli ambienti controllati permettono di costruire pipeline AI interne, con costi prevedibili e modelli verificabili.
Eseguire modelli in locale: la questione hardware
E qui arriviamo al nodo centrale: la memoria video (VRAM). La VRAM determina la dimensione massima del modello che si può caricare e la sua velocità di inferenza.
- Le GPU consumer (NVIDIA RTX 4090 o AMD 7900 XTX) arrivano a 24–32 GB di VRAM: già sufficienti per modelli da 7–13B, ma non oltre.
- Oltre questa soglia servono schede professionali o soluzioni con memoria condivisa, che unificano RAM e VRAM.
Memoria condivisa: un cambio di paradigma
Negli ultimi anni la distinzione tra RAM di sistema e VRAM della GPU si sta assottigliando. Nei sistemi tradizionali CPU e GPU hanno memorie fisiche separate: per elaborare un modello, i dati devono essere copiati avanti e indietro tra i due spazi, con un notevole costo in termini di banda e latenza. Le nuove architetture invece puntano a unificare la memoria, permettendo a CPU e GPU di accedere allo stesso spazio fisico, in modo coerente e ad altissima velocità. È un cambiamento che semplifica il calcolo e apre scenari nuovi per l’esecuzione di modelli AI di grandi dimensioni, anche su macchine compatte.
Tre approcci oggi particolarmente interessanti:
🧩 Apple Silicon (M3, M4, M4 Pro)
Apple è stata la prima a portare su larga scala il concetto di Unified Memory Architecture (UMA): CPU, GPU e Neural Engine condividono la stessa memoria fisica, a banda elevata (fino a 120 GB/s). Questo elimina la necessità di copiare i dati tra dispositivi e rende possibile caricare interamente un modello di grandi dimensioni (come un LLM da 13B) in un’unica area di memoria. L’efficienza energetica è eccellente, ma la memoria è saldato-on-chip e quindi non espandibile; i tagli disponibili (fino a 48–64 GB nelle versioni Pro/Max) restano piuttosto costosi.
⚡ NVIDIA DGX Spark (Grace Blackwell GB10)
Il DGX Spark, presentato al GTC 2025, rappresenta il primo sistema “personale” della linea DGX. Basato sul superchip NVIDIA GB10 Grace Blackwell, integra una CPU Grace a 20 core (10 Cortex-X925 + 10 Cortex-A725) e una GPU Blackwell di quinta generazione in un singolo package. Le due unità condividono 128 GB di memoria LPDDR5X coerente tramite NVLink-C2C, che fornisce una banda fino a 5× superiore a PCIe Gen 5. Il risultato è un modello di memoria CPU+GPU realmente unificato, con accesso coerente e senza copia dei tensor, capace di gestire fino a 200 miliardi di parametri (o 405B collegando due sistemi via ConnectX a 200 Gbps). Con un assorbimento di circa 240 W e dimensioni da mini-desktop (15 × 15 × 5 cm), il DGX Spark è una sorta di “AI workstation da scrivania”, ponte diretto tra le architetture UMA di Apple e i supercluster Grace Hopper dei data center.
🔥 AMD Ryzen™ AI Max+ 395 (Strix Halo)
Strix Halo segue una logica simile, ma in ambito consumer e con architettura x86. È una APU monolitica che integra CPU Zen 5 e GPU RDNA 3.5, condividendo fino a 128 GB di memoria LPDDR5X con banda teorica di 250–300 GB/s. Non ha VRAM dedicata: la GPU può allocare dinamicamente porzioni della RAM di sistema, come avviene nei Mac. Questo approccio consente di eseguire modelli di grandi dimensioni senza schede video discrete, con un ottimo compromesso tra prestazioni, costi e consumo energetico.
La mia esperienza con AMD Ryzen™ AI Max+ 395 (128 GB)
Sto sperimentando proprio questa piattaforma; esistono diverse soluzioni in commercio, io ho scelto frame.work desktop nella versione con 128GB di memoria. Come sistema operativo, utilizzo unicamente Linux.
Uno dei vantaggi è che, pur potendo configurare nel BIOS la quantità di memoria riservata alla GPU (ad esempio 512 MB), Linux gestisce dinamicamente la condivisione RAM/VRAM, come avviene nei sistemi Apple.
Per ottenere buone prestazioni è necessario impostare alcuni parametri del kernel relativi all’allocazione (nello specifico amdgpu.gttsize e ttm.pages_limit).
Il supporto software è in piena evoluzione:
- Kernel 6.18 introdurrà correzioni importanti per la gestione della memoria su Strix Halo.
- Driver Mesa e ROCm hanno guadagnato fino al +25 % di performance negli ultimi mesi.
- Tuttavia, instabilità e driver sperimentali rendono l’esperienza ancora poco “plug and play”.
Il bilancio complessivo è positivo: un rapporto costo/prestazioni molto interessante per chi vuole sperimentare LLM e modelli generativi senza GPU dedicate.
Toolbox e primi test pratici
Un ottimo punto di partenza sono le toolbox su GitHub di Donato Capitella, che semplificano l’esecuzione (ottimizzata per questo specifico hardware AMD) di llama.cpp, Qwen Image Studio, Wan Video Studio e ComfyUI.
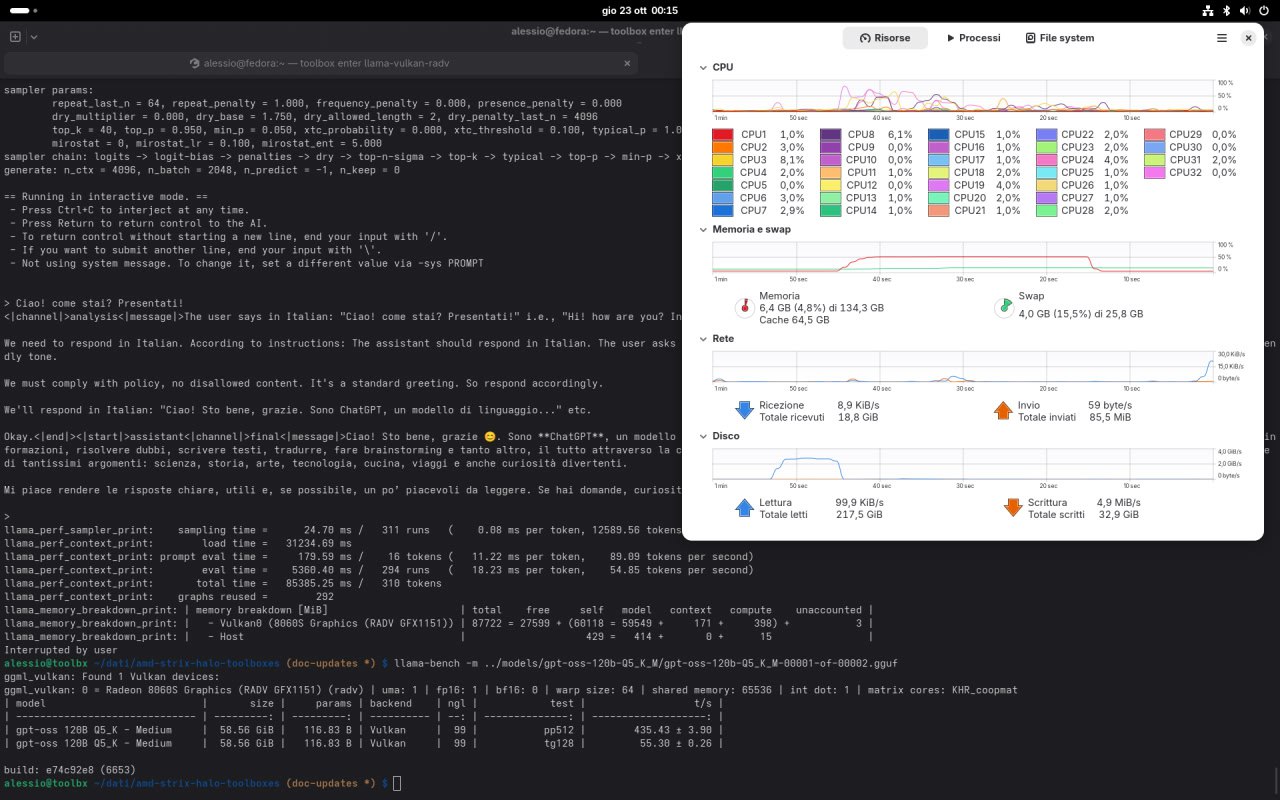
Ecco ad esempio un benchmark di esecuzione di GPT-OSS 120B con llama-bench, con il backend Vulkan abilitato:
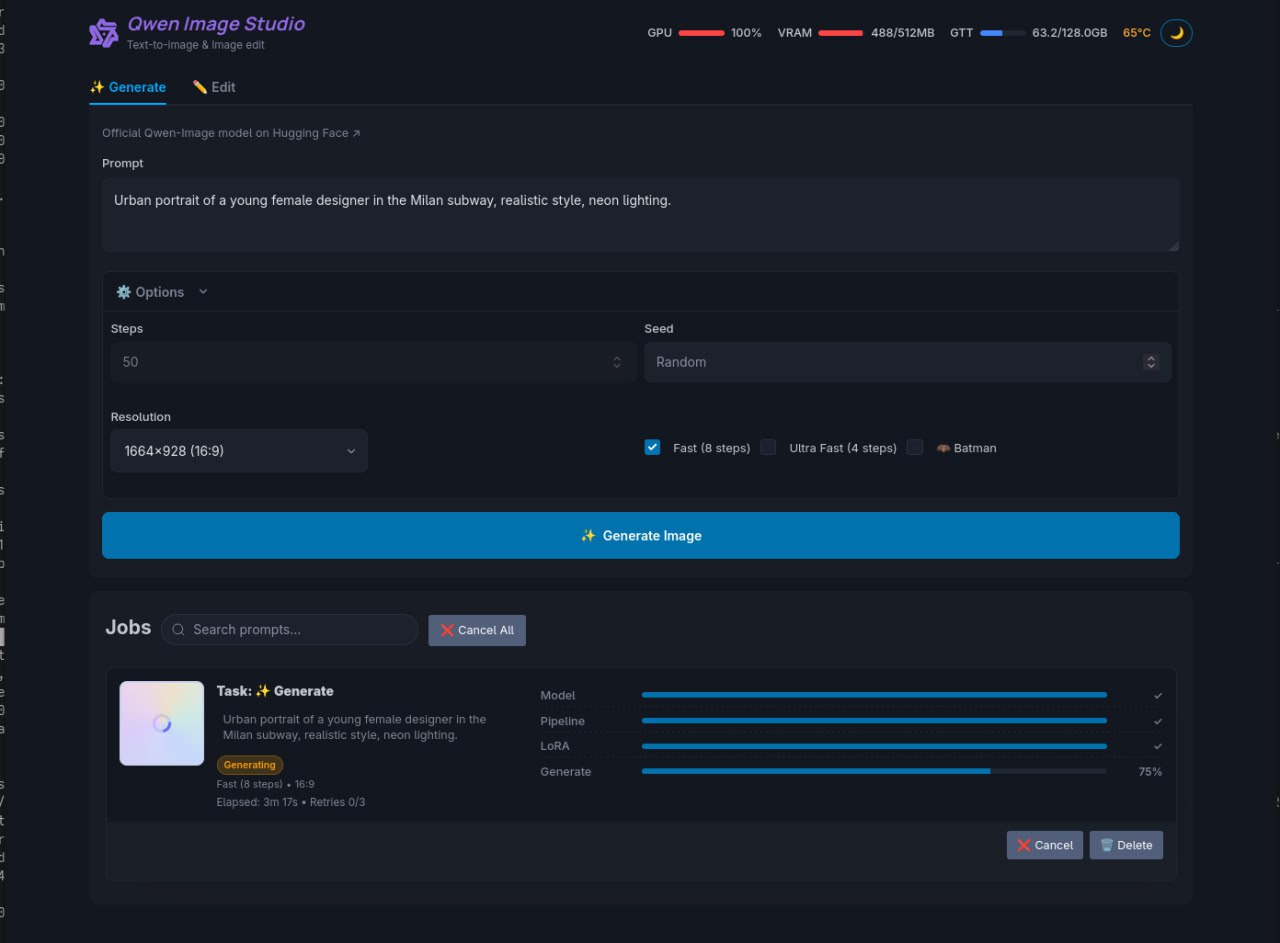
Interfaccia di generazione immagini Qwen Image Studio:

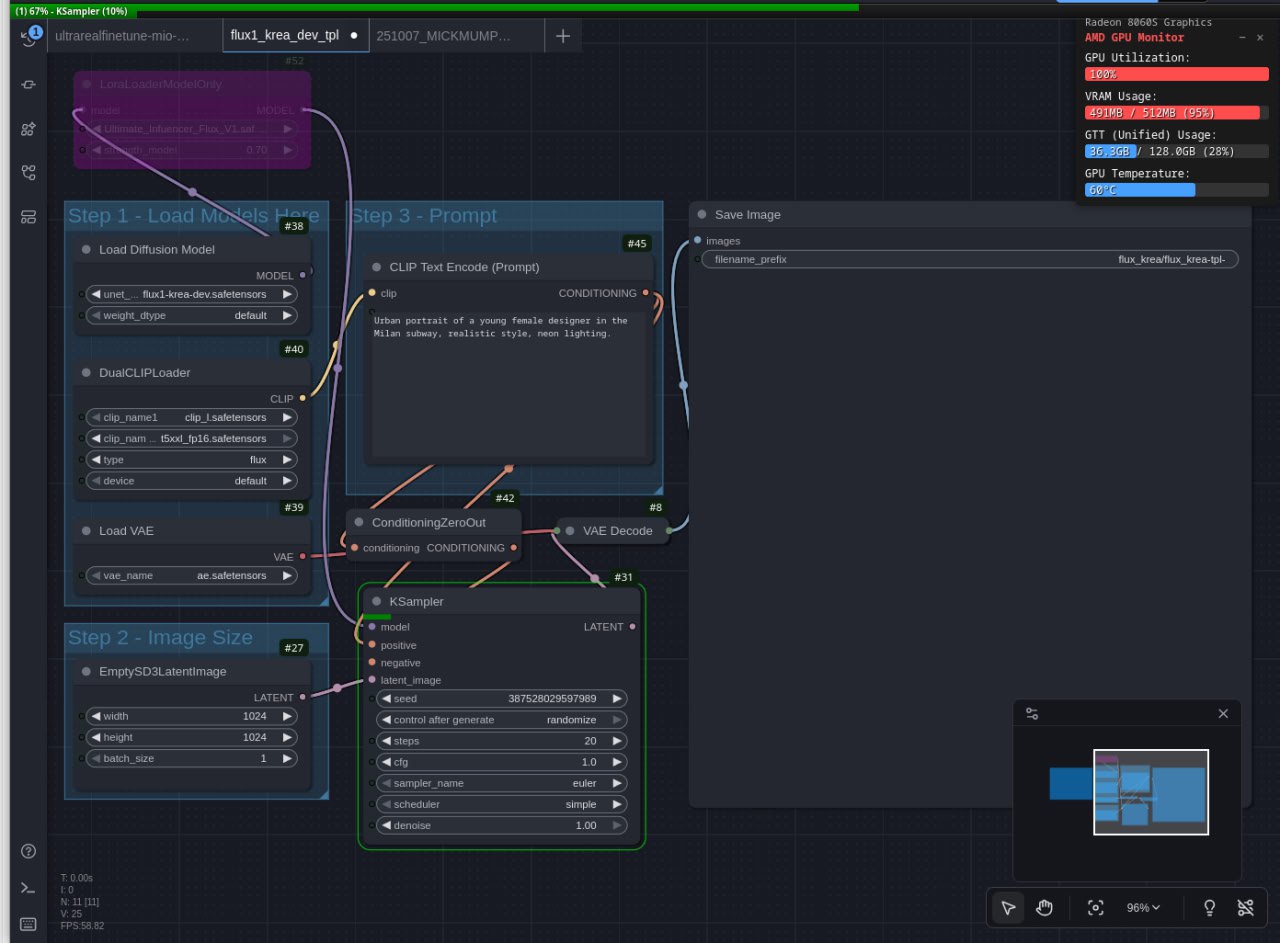
E un workflow di generazione ibrido con Flux Krea Dev dentro ComfyUI:
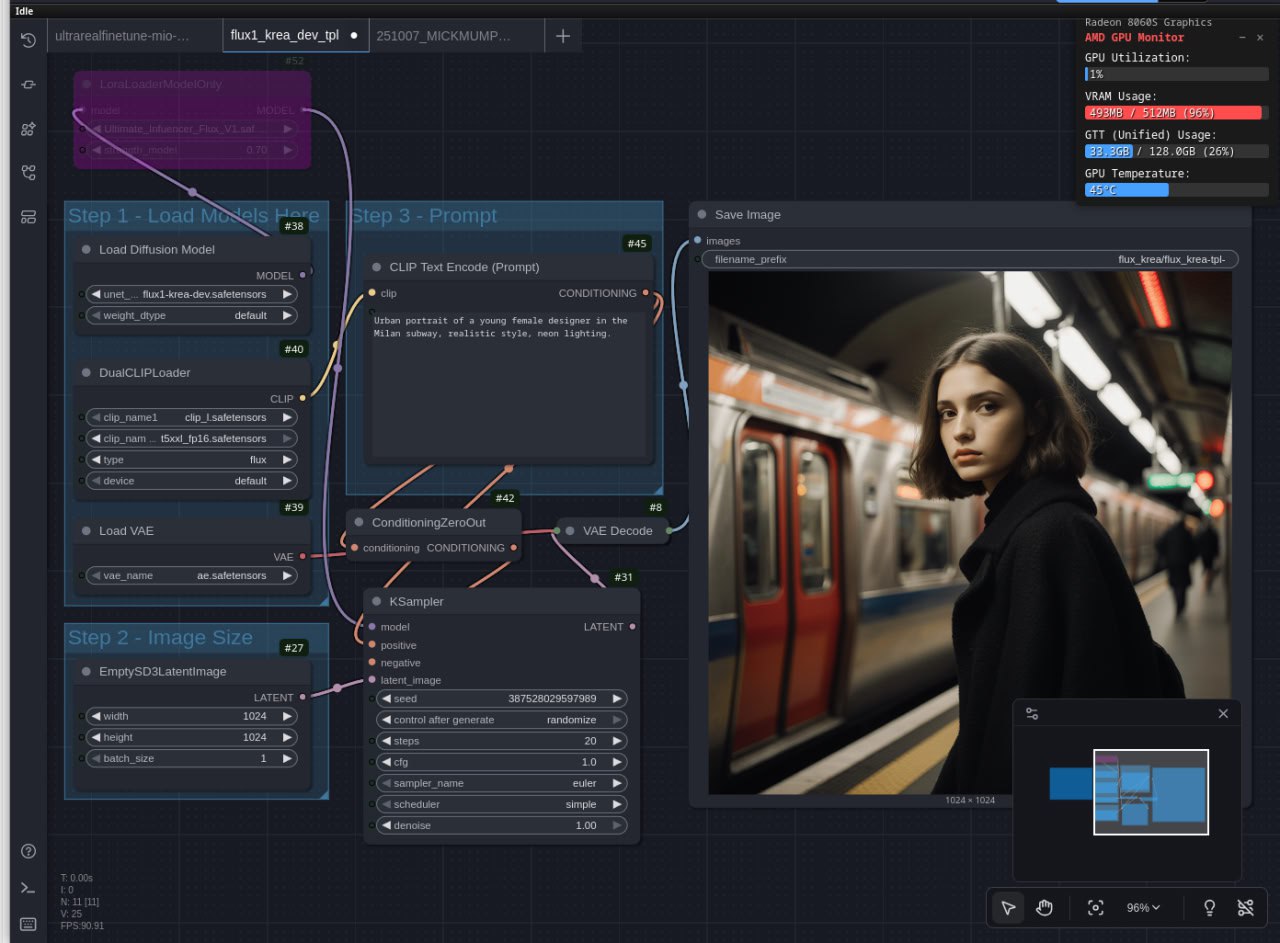
Considerazioni sulle configurazioni
Un aspetto curioso su Strix Halo: spesso le quantizzazioni BF16 risultano più efficienti di FP8, nonostante l’apparente “maggiore precisione”. Questo dipende dall’implementazione dei driver ROCm e dal modo in cui viene gestita la memoria condivisa: le operazioni FP8, pur teoricamente più leggere, introducono overhead nella conversione e nella gestione dei buffer.
Conclusione e prospettive
Eseguire modelli AI in locale o in ambienti controllati significa riappropriarsi del controllo su dati, costi e infrastruttura. Chiaramente non è ancora un percorso lineare: servono competenze tecniche, pazienza e una certa tolleranza ai bug quando si ha a che fare con driver e librerie sperimentali. Infine, in ambito consumer le soluzioni con memoria unificata e toolkit open-source consentono di ottenere risultati di discreta qualità in tempi ragionevoli.
Nei prossimi post racconterò alcuni use case concreti su Strix Halo, con esempi di automazione locale e generazione di contenuti multimodali.