
Introduzione
Negli ultimi mesi il numero di modelli eseguibili in locale per coding agent è cresciuto rapidamente: gpt-oss 20B e 120B, Qwen3-Coder, Qwen3-Coder-Next, GLM 4.5-Air, 4.6-Flash, 4.7-Flash sono solo alcuni esempi.
Se si dispone di una macchina con parecchia memoria – nel mio caso un AMD Ryzen AI Max+ 395 con 128GB di RAM unificata – la tentazione è semplice: verificare quanta memoria serve e scegliere il modello più grande che “ci sta”.
In pratica, però, la scelta è molto più sottile quando lo usecase non è un semplice chatbot. Per un coding agent la velocità diventa subito un aspetto critico, e la velocità non è un numero unico. In questo post provo a descrivere un possibile metodo di analisi basato su llama-bench, concentrandomi sugli aspetti di performance su singola richiesta.
Prompt processing speed e token generation speed
Quando si misura la velocità di un LLM locale, si guardano in genere due grandezze:
- Prompt processing speed (pps): quanti token al secondo il modello riesce a processare quando riceve un prompt.
- Token generation speed (tgs): quanti token al secondo riesce a generare in output.
Le due fasi sono molto diverse. Durante il prompt processing il modello deve leggere tutto il contesto (system prompt, file di codice, diff, tool output, cronologia) e costruire la KV cache. Solo dopo inizia la generazione token per token.
Nei grafici che seguono trovi le metriche pp512 e tg128:
pp512è la velocità media nel processare blocchi da 512 token.tg128è la velocità media nel generare 128 token.
Sono valori standardizzati che permettono confronti coerenti tra modelli e backend diversi.
Ambiente di test
I test sono stati eseguiti su:
- AMD Ryzen AI Max+ 395 (Strix Halo)
- 128GB di memoria unificata
- llama.cpp build: ff4affb4c (8067)
- backend:
- ROCm 7.2
- Vulkan (RADV)
ROCm è lo stack ufficiale AMD per il calcolo GPU basato su HIP. Vulkan, nel caso di Mesa RADV, è il driver open source che permette di usare la GPU via API Vulkan anche per workload compute. llama.cpp supporta entrambi, ma le differenze di comportamento possono essere significative, anche a parità di hardware.
Ho selezionato quattro modelli che ritengo interessanti per l’inferenza nel mio ambiente: la coppia di modelli gpt-oss da 20B e 120B che già avevo presentato in passato, GLM 4.7-Flash ossia la versione leggera (classe 30B) di quello che è stato il modello state-of-the-art di Z.ai fino a qualche giorno fa, e Qwen3-coder-next recentemente rilasciato da Qwen specificatamente per utilizzo con coding agents.
Conscio delle differenze in termini di qualità dei risultati ottenibili (che non sono però oggetto di discussione diretta in questo post) e dei diversi requisiti di memoria per le quantizzazioni prescelte, mi sono focalizzato sulle performance velocistiche.
1) Dimensione del contesto: il parametro -d
Ho eseguito i test con:
-d 0,8192,16384,32768,65536,131072
Il parametro -d in llama-bench simula la profondità del contesto, cioè il numero di token già presenti nella KV cache prima della misurazione. In altre parole, misura come si comporta il modello quando deve lavorare con 8k, 16k, 32k, 64k o 128k token già in memoria.
Questo è un punto fondamentale. I benchmark a contesto quasi nullo sono poco rappresentativi per un coding agent reale. Strumenti come Claude Code aggiungono molto contesto: file interi, diff, output dei tool, cronologia della conversazione. Ci vuole poco a superare i 50k-100k token.
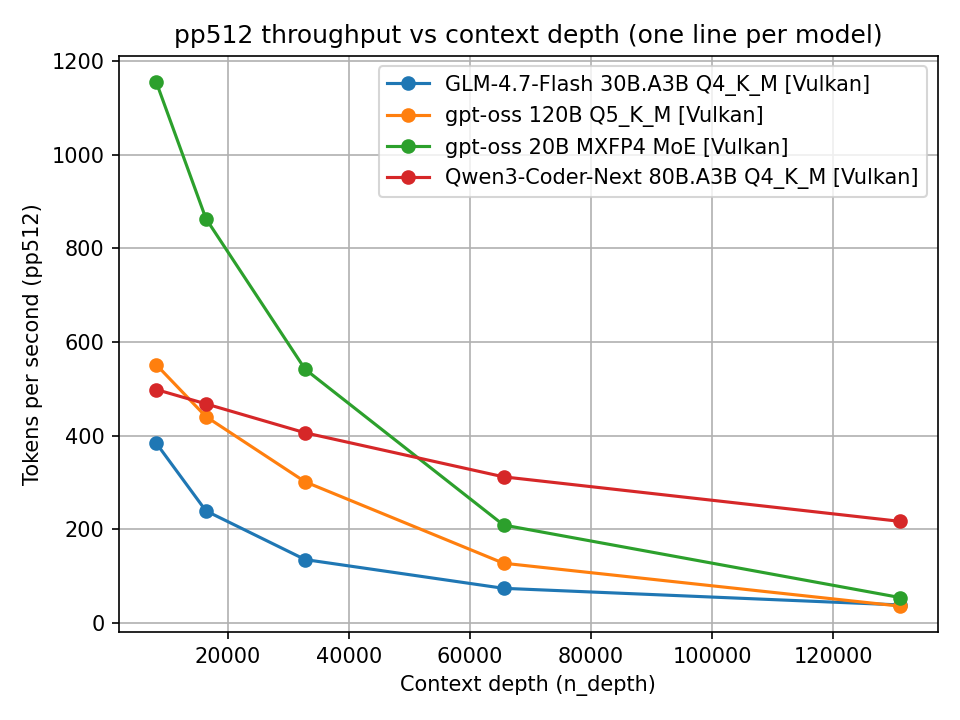
Guardiamo ad esempio il comportamento con backend Vulkan.
Prompt processing (Vulkan)
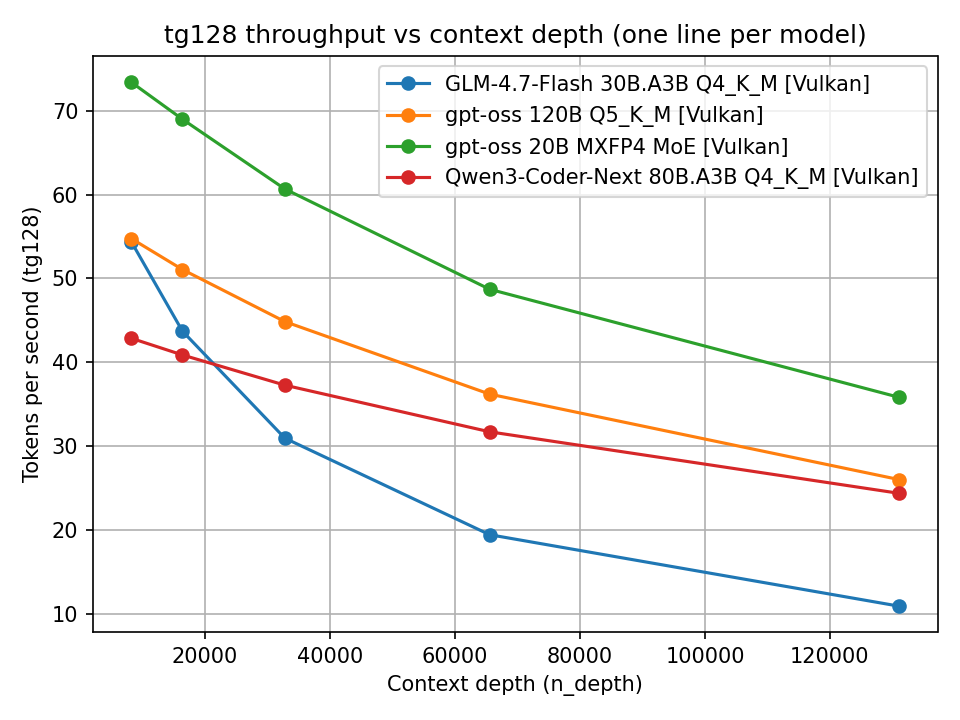
Token generation (Vulkan)
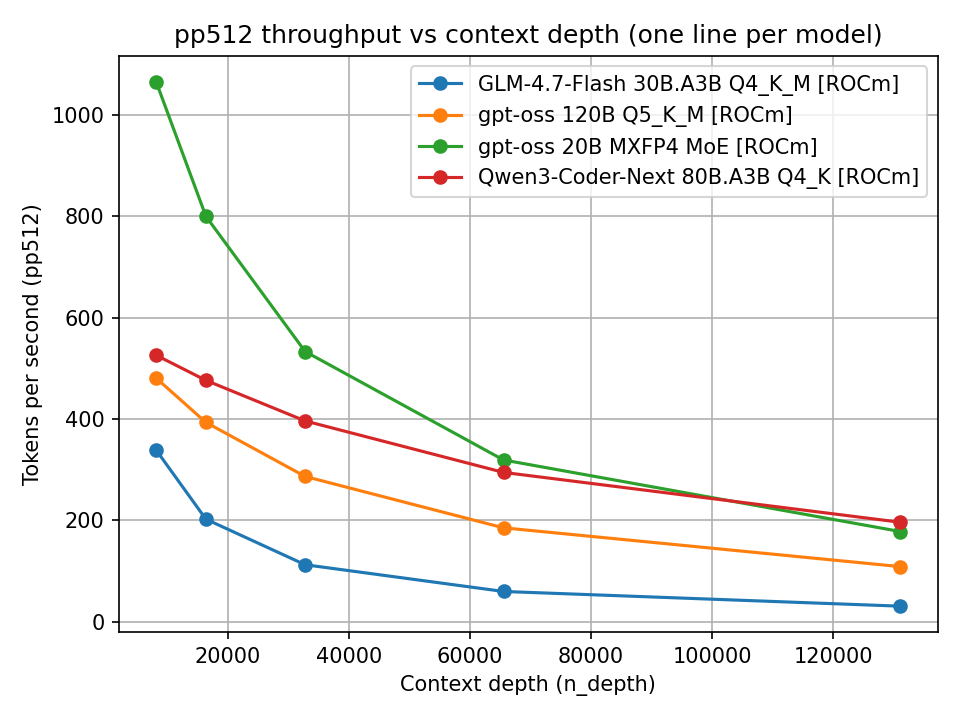
E lo stesso con ROCm:
Prompt processing (ROCm)
Token generation (ROCm)
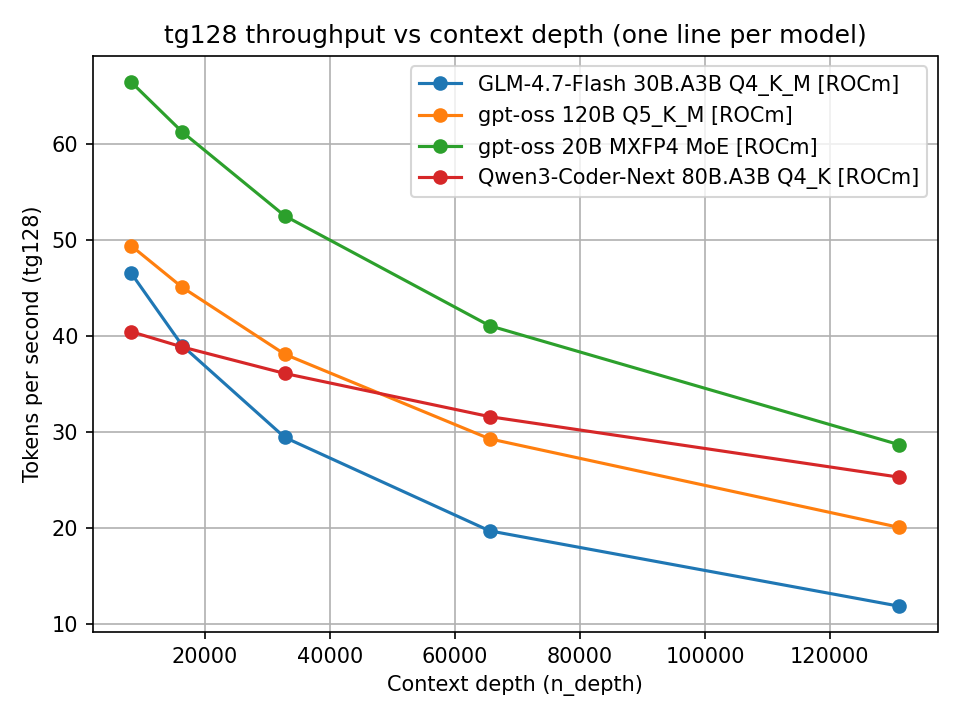
Si osserva chiaramente che sia pp512 sia tg128 degradano all’aumentare del contesto. La cosa interessante non è solo il valore assoluto, ma la pendenza della curva. Alcuni modelli partono veloci ma degradano rapidamente; altri mantengono un comportamento più stabile.
2) Testare con la stessa configurazione reale
Un errore frequente è eseguire benchmark con una configurazione e poi usare un’altra in produzione.
Se per l’inferenza userai llama-server con:
- un certo numero di layer in VRAM (
-ngl) - una specifica configurazione di flash-attention
- una determinata quantizzazione
- un backend preciso (ROCm o Vulkan)
allora llama-bench va eseguito nelle stesse condizioni. Altrimenti si stanno misurando numeri che non riflettono l’uso reale.
3) Le quantizzazioni non si comportano tutte allo stesso modo
Non basta guardare il numero di bit. Una quantizzazione può essere teoricamente più compatta o più veloce, ma non sfruttare in modo ottimale la precisione supportata dalla GPU o la gerarchia di memoria.
In pratica, alcune quantizzazioni risultano più memory-bound su certe architetture, mentre altre scalano meglio al crescere del contesto. Anche qui, l’unico modo serio per decidere è testare sul proprio hardware.
4) ROCm vs Vulkan: differenze concrete
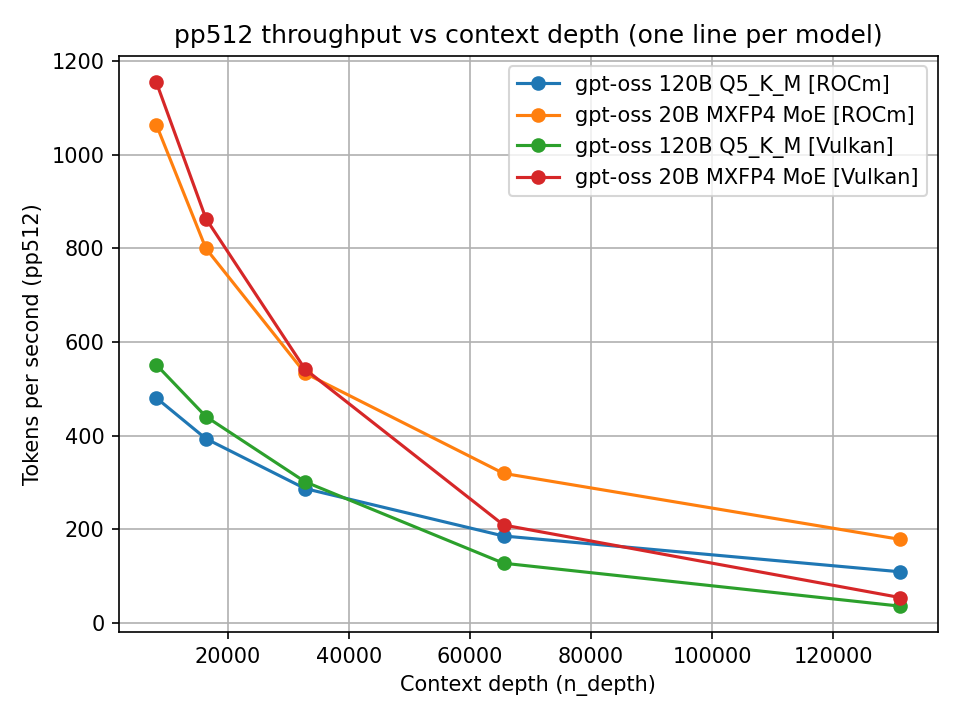
Un confronto diretto tra ROCm e Vulkan per gpt-oss mostra differenze non solo nei valori assoluti, ma anche nel modo in cui le prestazioni decadono con contesti grandi.
Prompt processing: ROCm vs Vulkan
Token generation: ROCm vs Vulkan
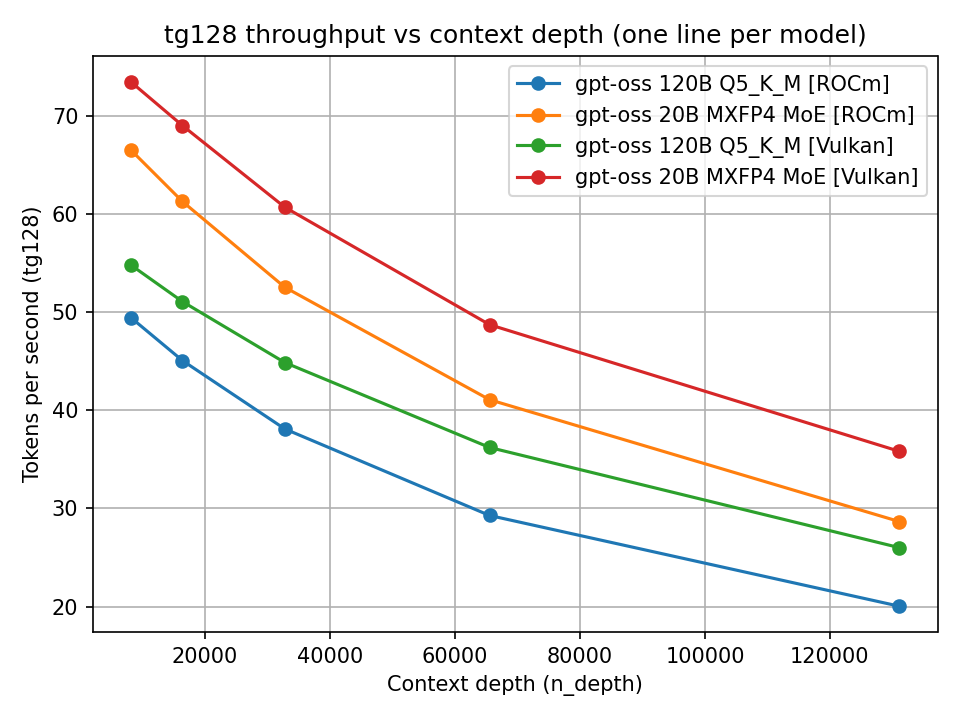
Un backend può essere più veloce a contesto piccolo ma degradare più rapidamente oltre i 32k o 64k token. Questo è particolarmente rilevante per i coding agent, dove il contesto tende a crescere rapidamente.
Perché, per un coding agent, il prompt processing conta più della generazione
Nel caso di un coding agent, il tempo speso nel processare il prompt è spesso predominante. Ogni volta che l’agente rilegge file, integra output di tool o ricostruisce il contesto dopo una tool call, il modello deve rieseguire la fase di prefill su un contesto potenzialmente molto grande.
La generazione, invece, spesso produce poche centinaia di token.
Se un modello degrada poco in token generation ma crolla in prompt processing oltre i 64k token, l’esperienza complessiva sarà comunque lenta. Al contrario, un modello con generazione leggermente più lenta ma con un prompt processing stabile su contesti grandi può risultare più reattivo nell’uso reale.
Nel mio caso specifico
Limitandoci a:
- richieste singole (niente concorrenza tra più client)
- parametri coerenti con la configurazione reale
- contesti fino a 128k token
- backend ROCm e Vulkan
tra i modelli testati (gpt-oss 20B, gpt-oss 120B, GLM 4.7-Flash, Qwen3-Coder-Next) il miglior compromesso complessivo, guardando in particolare al comportamento del prompt processing su contesti grandi, risulta essere Qwen3-Coder-Next.
Questo non significa che sia “il migliore in assoluto”. Non ho considerato:
- carichi concorrenti con più thread o client
- impatto di KV cache condivisa
- misure end-to-end con tool call reali
- qualità delle risposte in modo sistematico
Ma come primo filtro tecnico, un’analisi di questo tipo è molto più informativa del semplice confronto sulla dimensione del modello o sui token al secondo a contesto nullo.
Conclusione
Quando si sceglie un modello locale per un coding agent, limitarsi a verificare che “entri in memoria” è riduttivo.
Ha più senso:
- misurare sia prompt processing sia token generation;
- analizzare il decadimento al crescere del contesto;
- usare la stessa configurazione che si adotterà in inferenza;
- confrontare backend e quantizzazioni sul proprio hardware.
Nel caso dei coding agent, la partita si gioca spesso nella fase di prompt processing. È lì che si accumula la latenza maggiore e dove le differenze tra modelli diventano evidenti.
Il resto, come sempre, va validato sul proprio caso d’uso reale.