
Un tema ricorrente in ambito di intelligenza artificiale generativa applicata alle immagini (e video) è quello della creazione di personaggi consistenti, consistent characters, cioè la capacità di un modello AI di rappresentare lo stesso soggetto (volto, corporatura, stile, dettagli) in scatti completamente diversi, prodotti in momenti, contesti e pose differenti. È un tema che sta esplodendo: dai video su YouTube, agli influencer virtuali su Instagram, passando per tool online che permettono di farsi il proprio “avatar AI”… e includendo ricerche e progetti molto più seri attorno al tema della verifica identità, deepfake, contenuti generati per social o advertising.
Su Aladino Digitale già si era toccato l’argomento nel post su Giulia che esce dalla lampada. In quel caso l’idea era sostanzialmente un gioco: avevamo generato un’immagine con ChatGPT + Gemini Nano Banana + OpenArt, e poi l’avevamo usata per ottenere qualche close-up e un mini-video. Ma lì si trattava semplicemente di sfruttare le funzionalità di modelli img2img come Flux Context (funzionalità che oggi possiede anche Gemini Nano Banana) esposte da tool quali OpenArt: non c’era un vero “personaggio consistente”. Era una serie di derivazioni della stessa immagine.
Quello che volevo esplorare ora è un passo diverso: partire da una singola foto e costruire un modello in grado di generare ogni possibile nuova immagine di quel soggetto, in qualunque contesto, come se fosse una vera persona fotografata infinite volte.
E per farlo ho scelto di restare in locale, usando la mia macchina con AMD Strix Halo, modelli di architettura Flux, ComfyUI e un LoRA addestrato da zero.
Di seguito racconto l’esperimento, eseguito “per davvero”, con tutti i limiti del caso.
1. Perché un “personaggio consistente” è diventato così importante (e perché interessa anche a noi)
Il concetto è semplice: se voglio creare un personaggio fittizio (per storytelling, social, mockup di campagne, giochi, fumetti, concept art) un singolo scatto non basta. Voglio la stessa persona che:
- sorride, è seria, guarda di lato;
- sta in piedi, seduta, di profilo;
- è in cucina, in un bar, in un parco;
- indossa abiti diversi;
- è ripresa con stili e qualità fotografiche differenti.
Oggi le AI sfornano volti realistici a migliaia… ma mantenere coerenza e consistenza tra generazioni differenti è un’altra storia. Ecco perché sono nati svariati siti online (incluso lo stesso OpenArt) che promettono di generare in modo semplice un consistent character: da poche immagini costruiscono un profilo consistente, sfruttando in qualche forma un fine-tuning leggero del modello (quasi sempre LoRA).
Nel mio caso, volevo capire:
- cosa succede facendolo tutto in locale, senza mandare foto a servizi terzi;
- cosa cambia rispetto alle soluzioni “one click” online;
- se è possibile partire davvero da una sola immagine e arrivare a un modello funzionante.
Giulia è diventata la “cavia” perfetta.
2. LoRA, Flux e il contesto “AI in locale”: cosa serve davvero
Avevo menzionato i LoRA già in passato nel post sulla scelta dei modelli da usare in locale; qui aggiungiamo qualche info aggiuntiva riguardo LoRA e sulle altre scelte fatte:
Che cos’è un LoRA?
- È un fine-tuning leggero, cioè una piccola rete aggiuntiva che modifica selettivamente il comportamento del modello base.
- Non si riaddestra tutto da zero (operazione impossibile in locale), ma solo pochissimi parametri aggiuntivi.
- Il risultato è un file (tipicamente in formato
safetensors) molto leggero, in genere pochi megabyte.
In pratica un LoRA è come un filtro che dice al modello:
“Quando vedi la parola chiave X, usa questo pattern di volto, proporzioni, dettagli”.
Perché Flux?
Perché al momento:
- è estremamente forte sul realismo (specie nella versione Krea);
- regge molto bene l’identità del soggetto;
- ha modifiche ottimizzate per generazione rapida, queuing, caching, ecc.;
- è molto apprezzato dalla community e supportato da tanti tool
- gira relativamente bene sulla soluzione AMD a mia disposizione.
Perché in locale?
In linea di principio, l’approccio in locale offre il vantaggio di avere un flusso completamente privato e consente di sperimentare senza troppe preoccupazioni riguardo il costo dei token. Da un punto di vista più personale, invece, volevo capire i limiti pratici provando un caso d’uso concreto sul mio hardware.
Il resto del post è quindi la cronaca di questo processo: creazione di un opportuno dataset → training del LoRA → test del LoRA e valutazioni finali.
3. Costruzione del dataset: il vero collo di bottiglia
È quasi paradossale, ma produrre un buon dataset di immagini è complesso (e importante!) quanto addestrare il LoRA.
Io ho deciso di usare e riportare qui due strade:
3.1 – Generazione con Gemini Nano Banana via OpenArt.ai (approccio “online”)
Partendo dall’immagine di Giulia usata nel vecchio post, ho aperto OpenArt in modalità Chat Edit e ho iniziato a chiedere di:
- togliere oggetti;
- cambiare ambienti;
- effettuare zoom su dettagli;
- cambiare posa;
- aggiungere abiti;
- ecc.
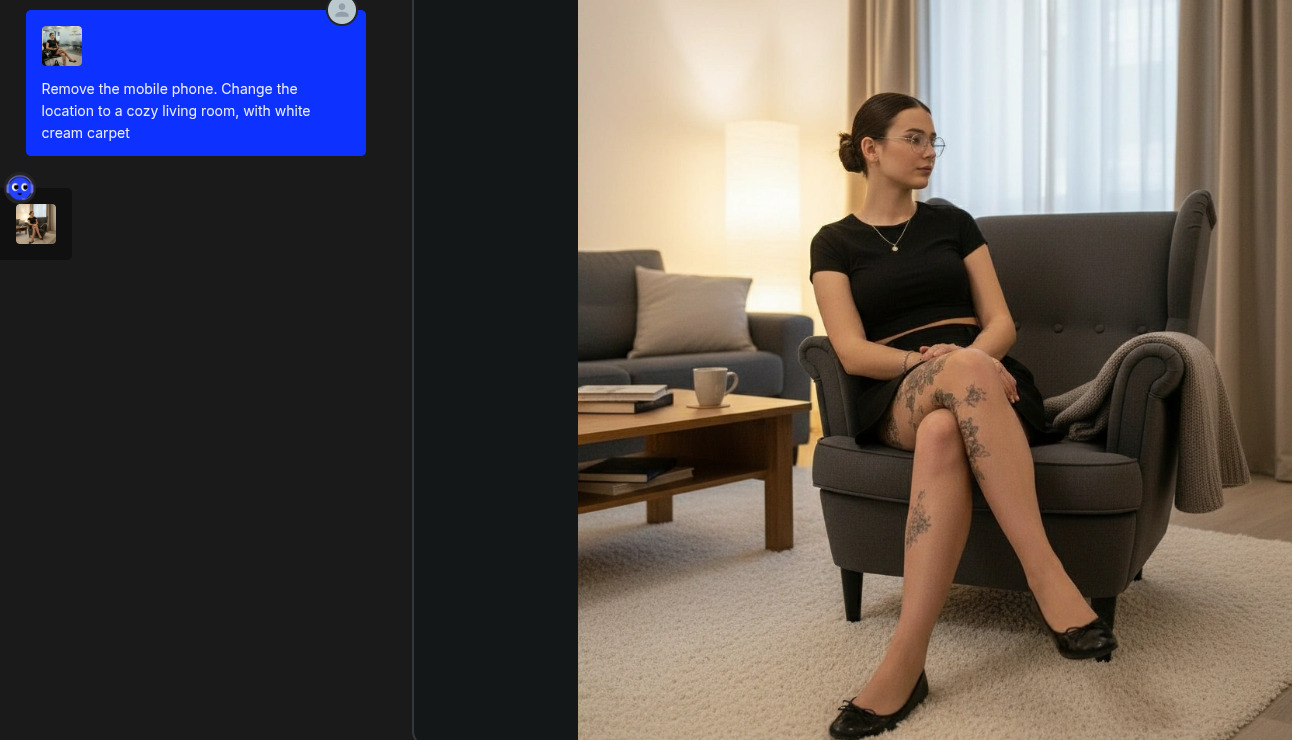
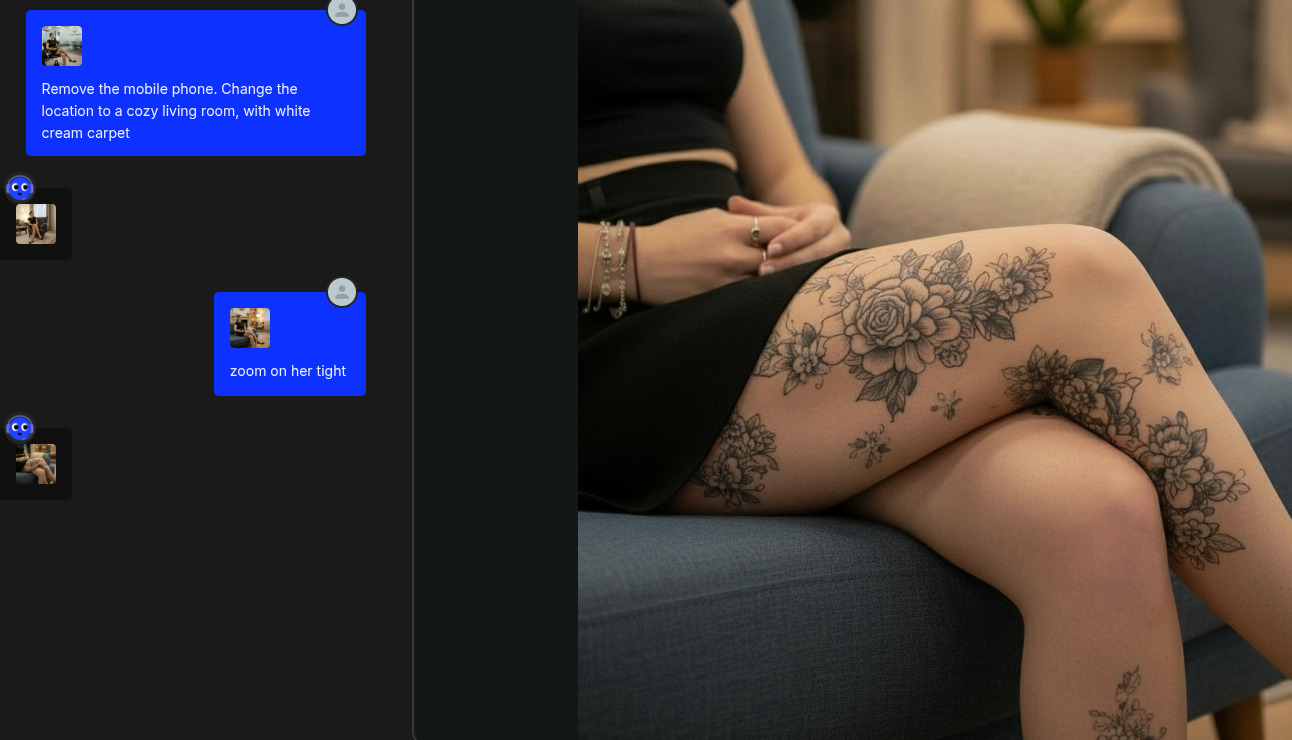
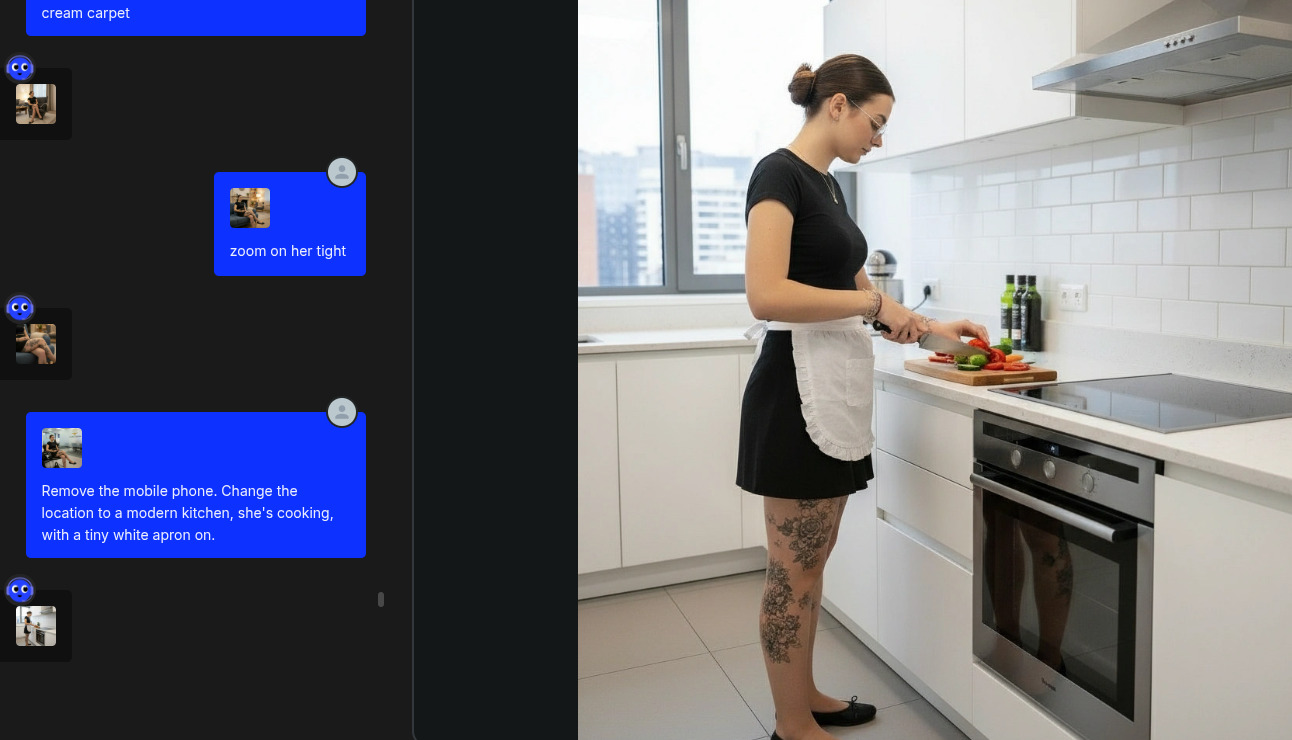

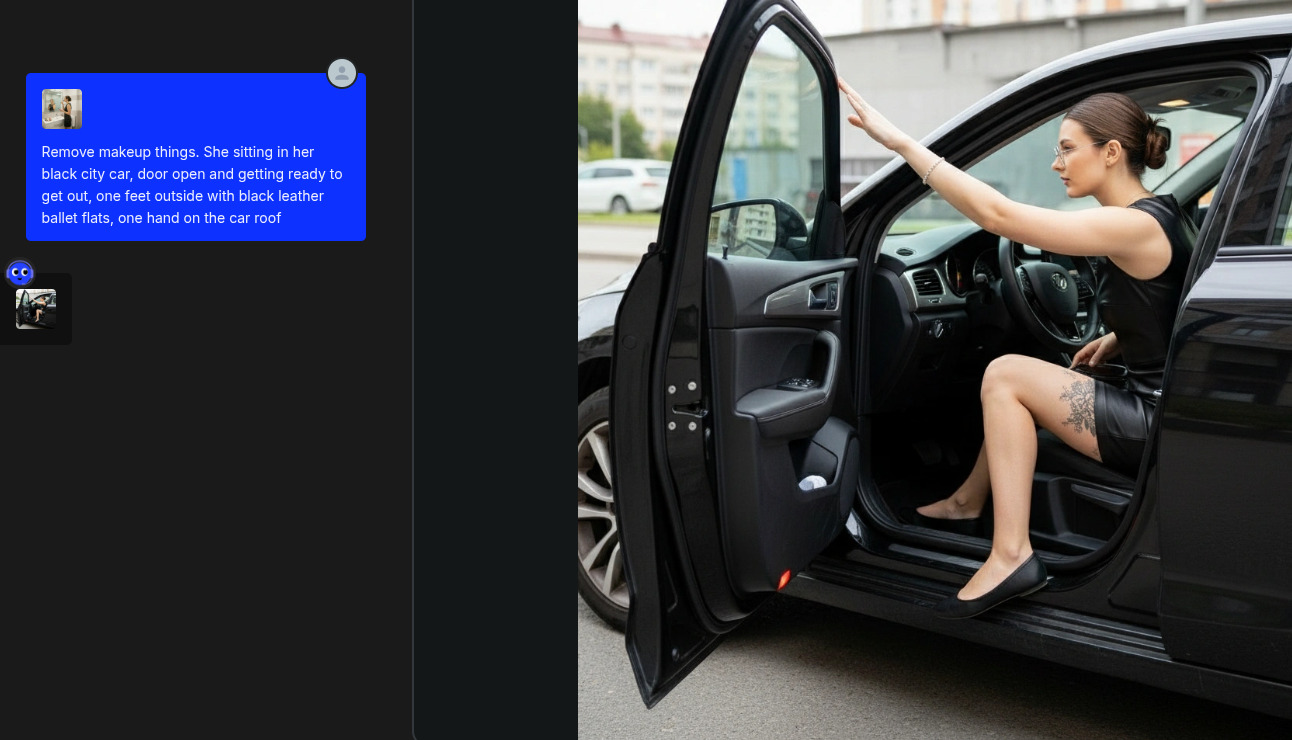
Il vantaggio di questo approccio è la rapidità di generazione delle immagini, che sono di norma coerenti e senza particolari allucinazioni (grazie alla bontà di Gemini Nano Banana). Il limite vero, a prescindere da ragionamenti su costi, è chiaramente quello di privacy, policy ed eventuale moderazione.
Ho comunque incluso alcune di queste immagini nel dataset finale perché erano molto utili come pose alternative.
3.2 – Generazione con ComfyUI (approccio “locale”, più complesso ma più controllabile)
Qui entra in scena un workflow abbastanza articolato; dopo una breve ricerca in rete, ho deciso di provare quello rilasciato e descritto pubblicamente da Mickmumpitz il mese scorso. Il flusso è diviso in due parti; nella prima ComfyUI:
- genera viste front / side / back del personaggio (turnaround sheet);
- produce close-up coerenti del volto;
- cambia espressioni attraverso controlli fini dei movimenti di bocca, naso, occhi, sopracciglia, etc;
- genera pose diverse attraverso controlli specifici e/o immagini di riferimento;
- cambia l’abbigliamento del soggetto usando capi da immagini di riferimento;
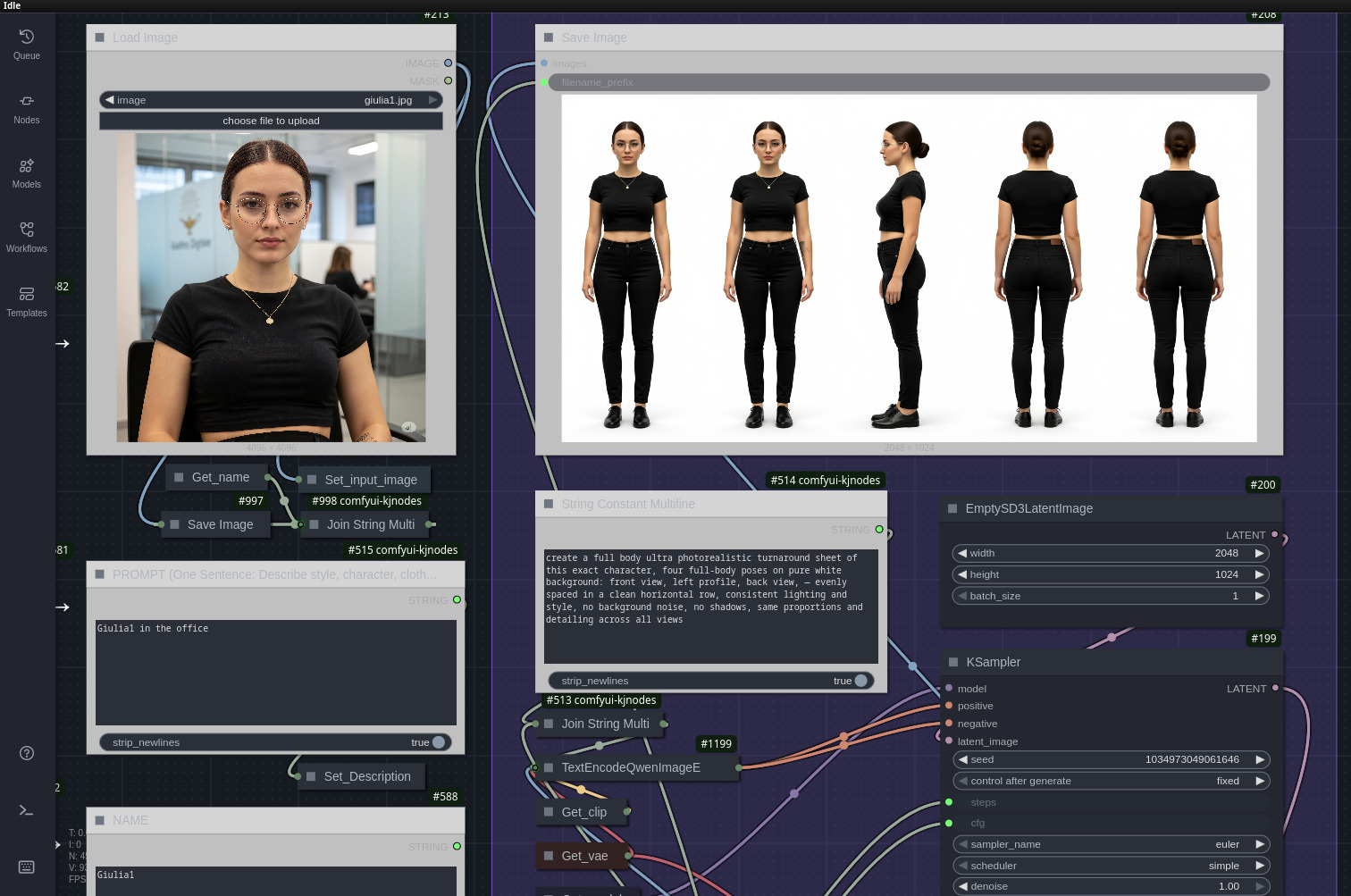
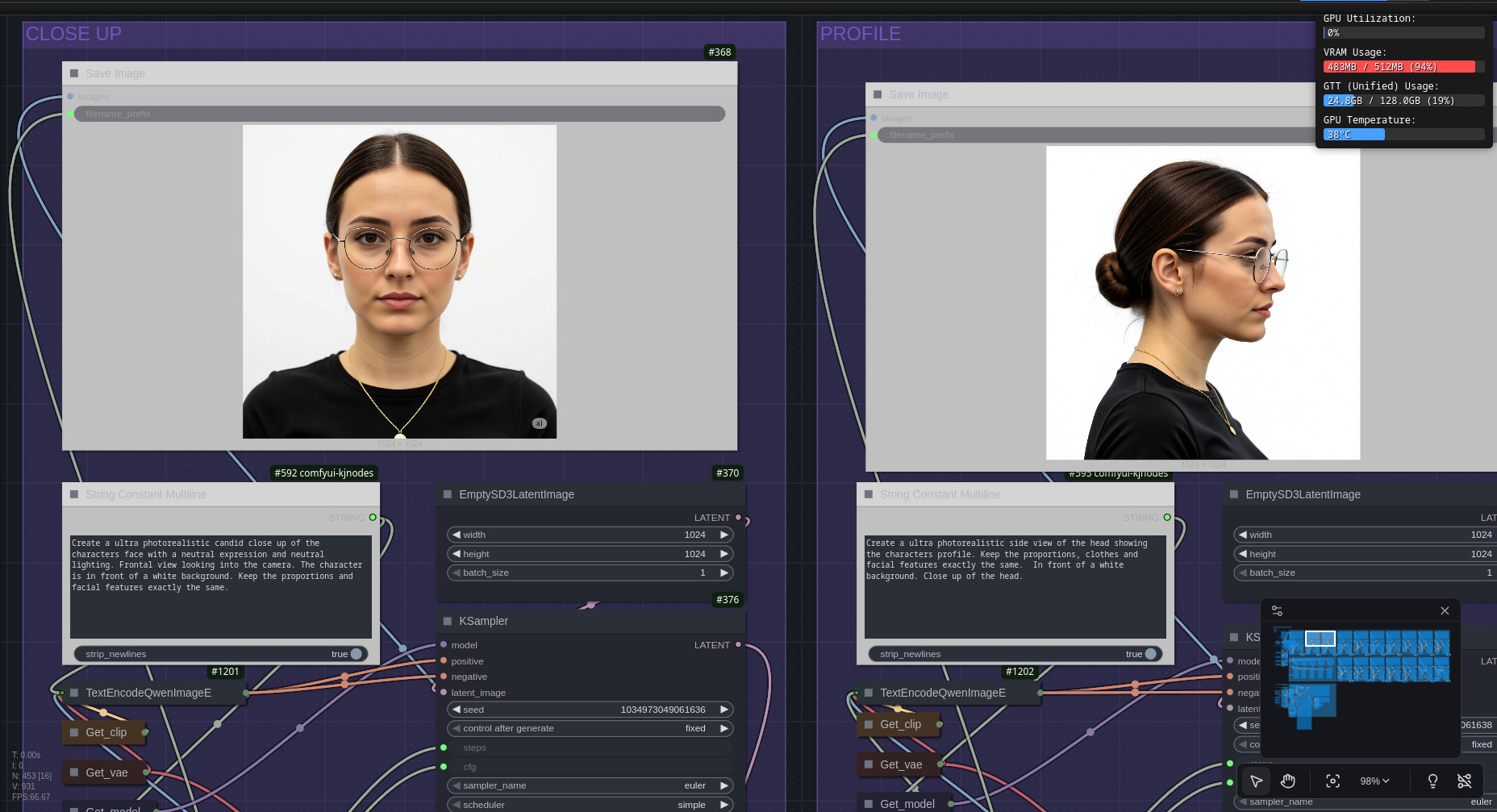
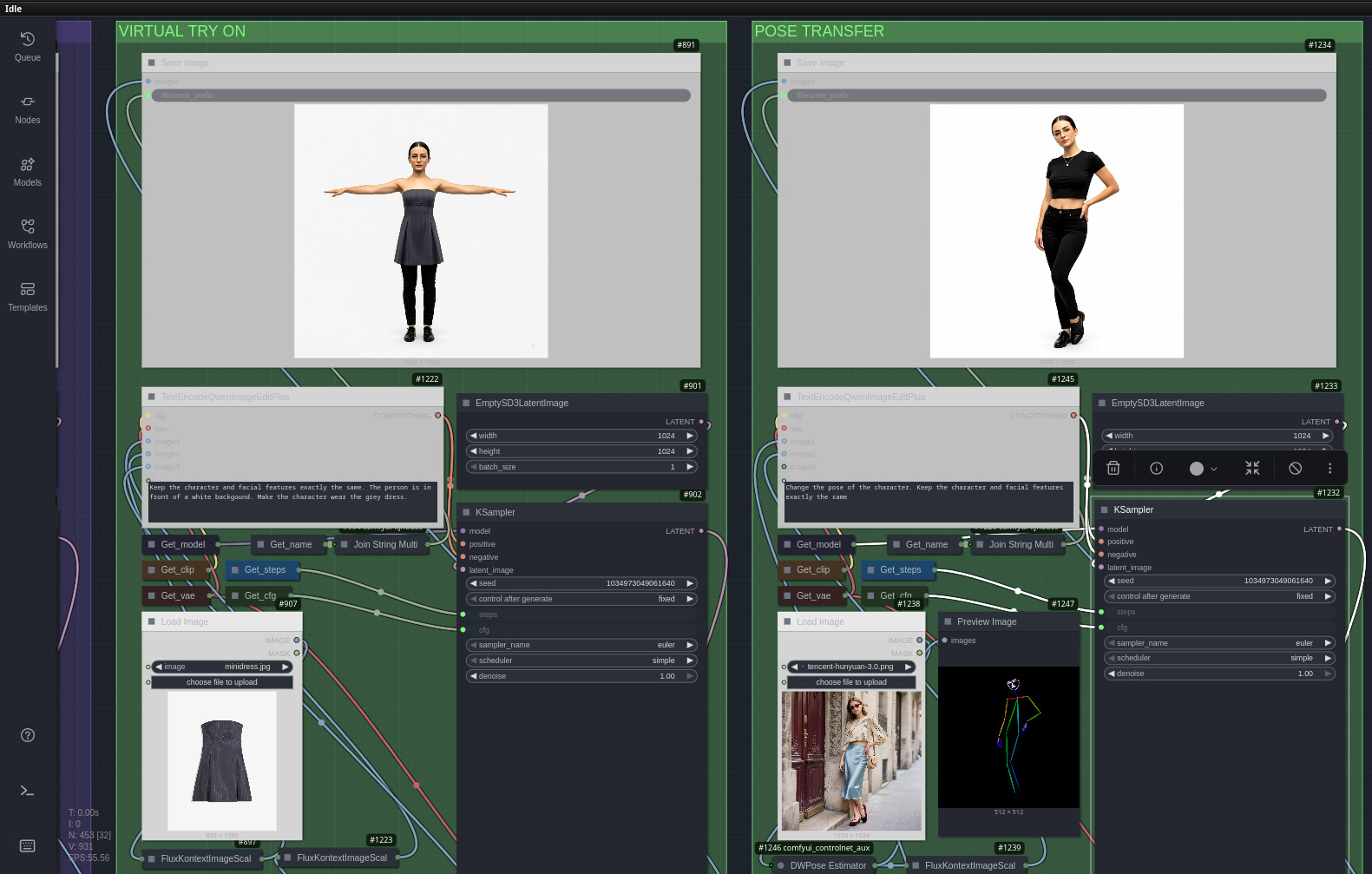
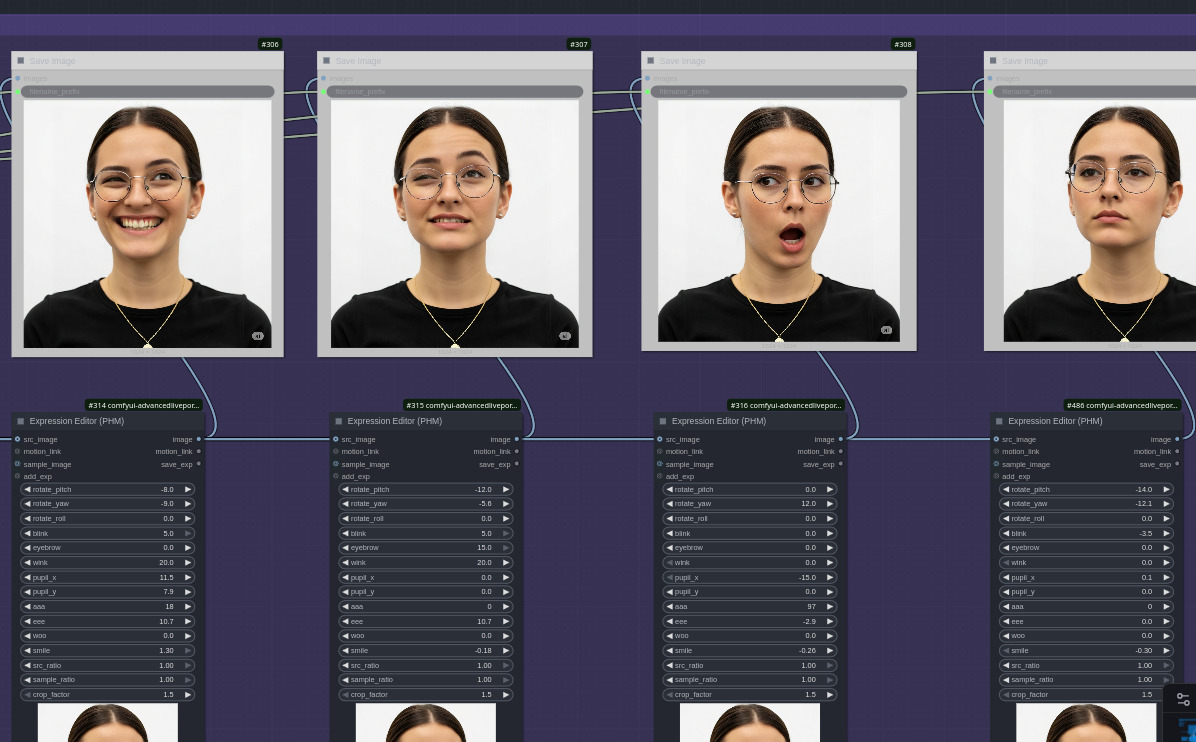
Nella seconda parte invece si applica upscaling e piccoli miglioramenti assortiti alle immagini precedentemente generate. Vengono inoltre generate le caption con la descrizione delle immagini create.
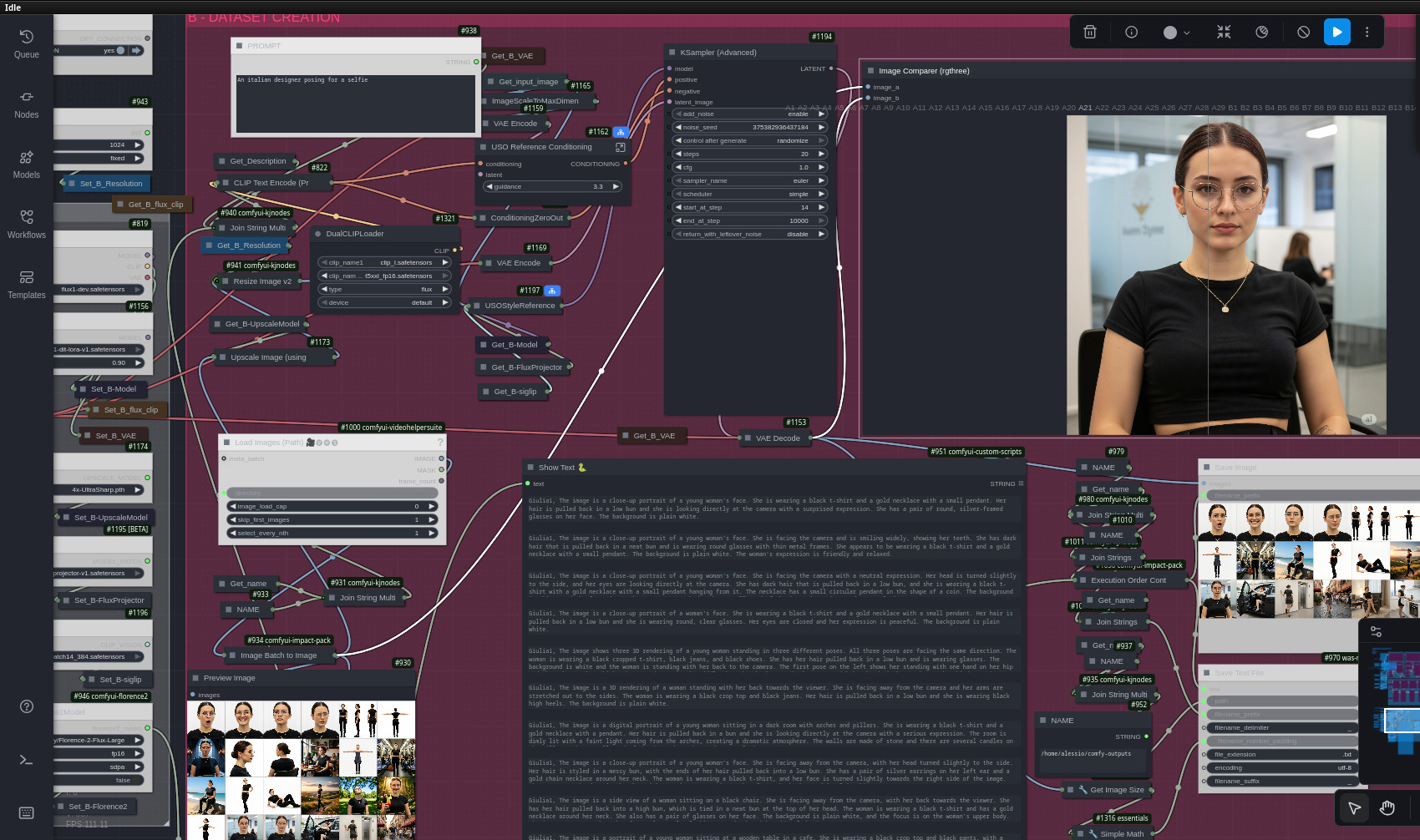
Il risultato è un dataset relativamente strutturato, con viste complementari che aiutano il LoRA a generalizzare.
Vantaggi
- Tutto locale, massima privacy.
- Controllo diretto su qualità e varietà delle immagini (pose, espressioni, luci).
Limiti
- Workflow non banale da capire.
- Richiede tempo e risorse (VRAM); per non impiegare giorni e dovendo fare i conti con alcune instabilità del mio stack (sto sempre aspettando l’uscita del kernel 6.18 di Linux…), nel fare upscaling mi sono limitato ad immagini 1024x1024 pixel di dimensione.
A dataset completo, avevo circa 25 immagini ben varie. Sufficienti per un LoRA di qualità? Forse, da valutare in seguito, di sicuro abbastanza per un primo esperimento attendibile… e soprattutto: tutto costruito da una sola immagine originale.
4. Addestrare il LoRA con FluxGym: semplice, ma con mille parametri
Per l’addestramento ho usato FluxGym, un’interfaccia che permette di:
- definire il nome del LoRA;
- scegliere il modello base (Flux dev nel mio caso) e la parola chiave/trigger per attivare il LoRA;
- caricare immagini + caption automatiche;
- impostare epoche, batch size, repeats, LR;
- visualizzare lo script generato per effettuare il training ed eventualmente eseguirlo.
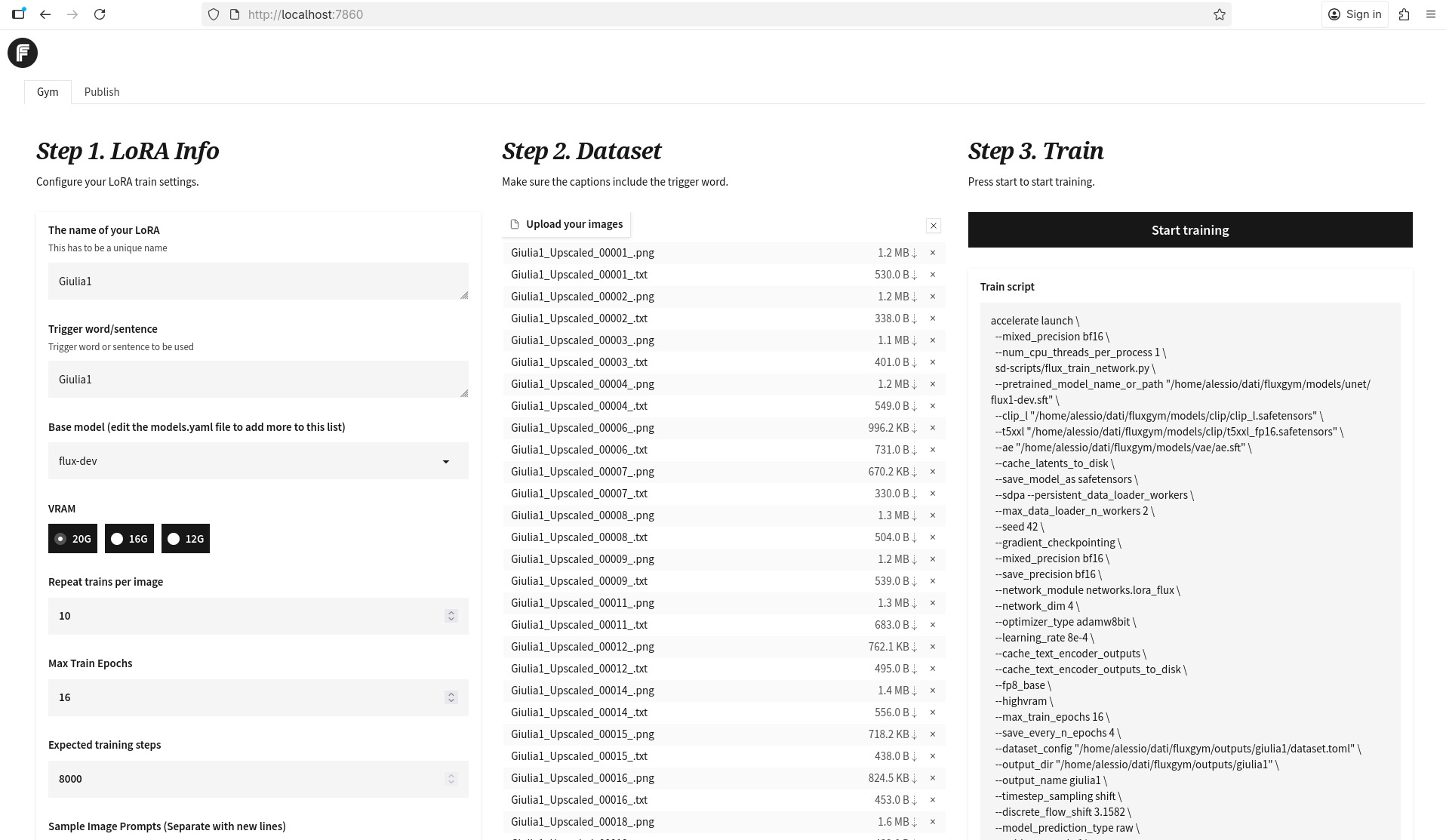
Caricamento immagini
Ho selezionato le 25 immagini del dataset descritte in precedenza; i file .txt generati dal workflow ComfyUI e contenenti le caption vengono caricati automaticamente (purtroppo la qualità e coerenza del testo che descrive le scene è quello che è):
Configurazione usata
FluxGym dispone di diverse decine di parametri di configurazione.
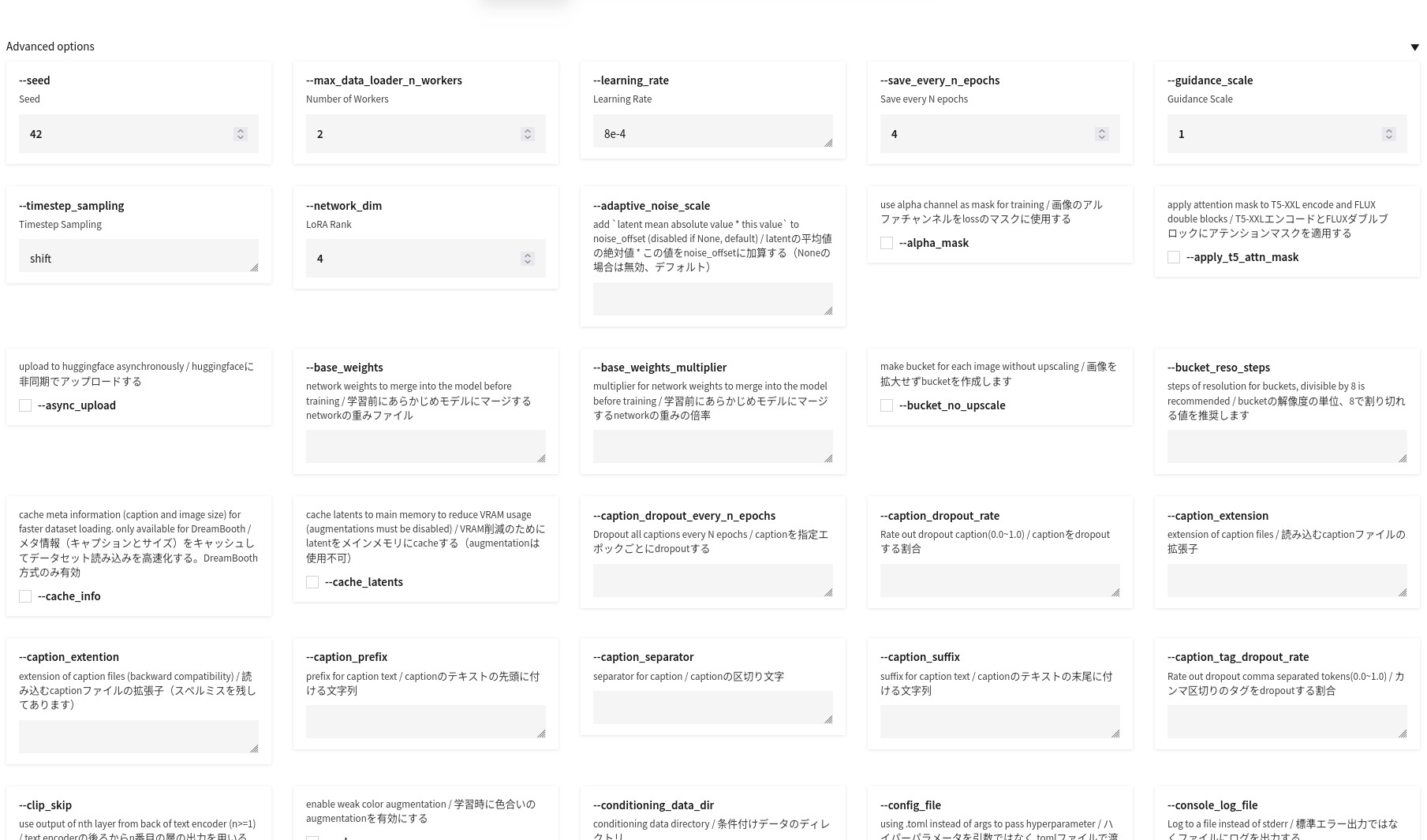
Per semplicità, ho scelto di non focalizzarmi sugli aspetti di “ottimizzazione scientifica”: ho modificato soltanto --optimizer-type per evitare un errore iniziale e la durata del training, poi ho lasciato quasi tutto a default.
accelerate launch --mixed_precision bf16 --num_cpu_threads_per_process 1
sd-scripts/flux_train_network.py
--pretrained_model_name_or_path "/home/alessio/dati/fluxgym/models/unet/flux1-dev.sft"
--clip_l "/home/alessio/dati/fluxgym/models/clip/clip_l.safetensors"
--t5xxl "/home/alessio/dati/fluxgym/models/clip/t5xxl_fp16.safetensors"
--ae "/home/alessio/dati/fluxgym/models/vae/ae.sft"
--cache_latents_to_disk
--save_model_as safetensors
--sdpa
--persistent_data_loader_workers
--max_data_loader_n_workers 2
--seed 42
--gradient_checkpointing
--mixed_precision bf16
--save_precision bf16
--network_module networks.lora_flux
--network_dim 4
--optimizer_type adamw
--sample_prompts="/home/alessio/dati/fluxgym/outputs/giulia1/sample_prompts.txt"
--sample_every_n_steps="100"
--learning_rate 3e-4
--cache_text_encoder_outputs
--cache_text_encoder_outputs_to_disk
--fp8_base
--highvram
--max_train_epochs 16
--save_every_n_epochs 4
--dataset_config "/home/alessio/dati/fluxgym/outputs/giulia1/dataset.toml"
--output_dir "/home/alessio/dati/fluxgym/outputs/giulia1"
--output_name giulia1
--timestep_sampling shift
--discrete_flow_shift 3.1582
--model_prediction_type raw
--guidance_scale 1
--loss_type l2
--mem_eff_attn
E’ possibile fornire uno o più sample prompt da utilizzare a varie epoche per generare immagini con il LoRA corrente, così da valutare i progressi dell’addestramento (ed eventualmente fermarsi ante tempo, previa configurazione di FluxGym per salvare snapshot del LoRA agli stessi step in cui si valutano i sample prompt). In generale, qui il consiglio è di fornire prompt sufficientemente generici da lasciare spazio al modello di “esprimersi” e vedere se e quanto il LoRA sta facendo effetto. Inoltre è bene formulare prompt che descrivano scene che normalmente portino a rappresentare gli elementi che si presume essere distintivi del soggetto per i quale si crea il LoRA (ad esempio ripresa frontale del soggetto , utile per valutare il viso).
Dopo diverse ore di computazione, utilizzando oltre 20 GB di memoria video (ma esiste configurazione per eseguire con soli 12GB di VRAM), FluxGym mi produce:
giulia1.safetensors→ il LoRA finale- vari snapshot intermedi
- immagini sample
- caption associate
Non immediato di sicuro, ma perfettamente gestibile sul mio hardware.
5. Risultati: il LoRA funziona davvero? Sì (ma con alcune sorprese)
Il LoRA ottenuto è utilizzabile con qualunque modello della serie Flux. Torno dunque in ComfyUI, carico un workflow Flux standard, ma decido di utilizzare Flux1 Krea Dev per un maggiore fotorealismo delle immagini generate; per caricare il LoRA, uso un apposito LoraLoaderModelOnly e seleziono il file .safetensor finale generato da FluxGym.
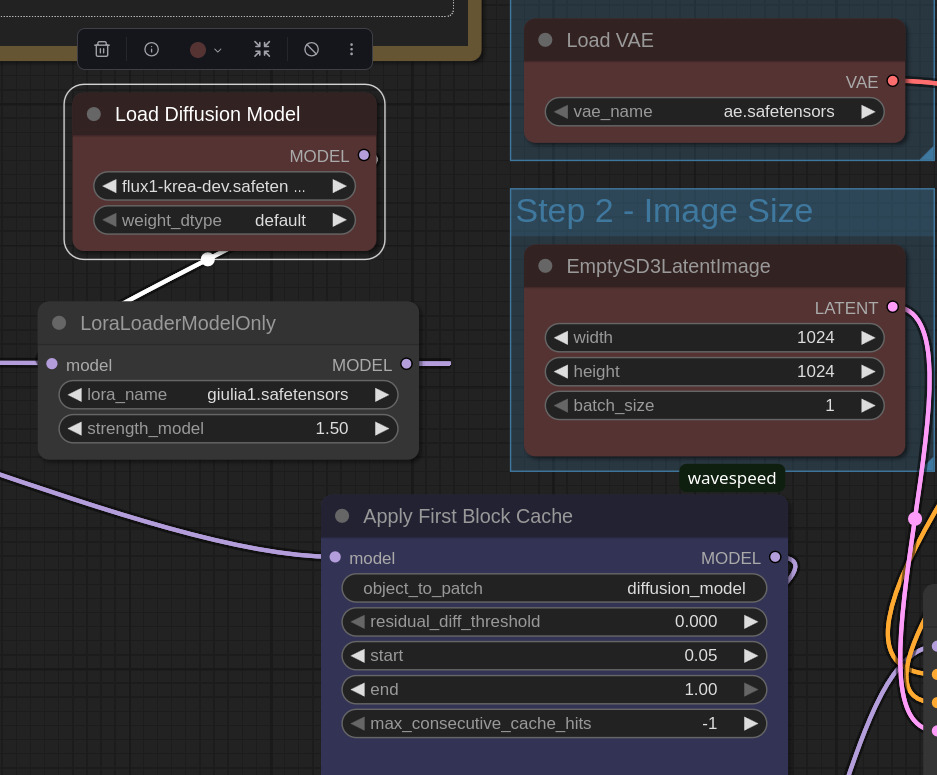
Per attivare il LoRA in fase di generazione, aggiungo nel prompt la parola chiave Giulia1 e gioco con i contesti.
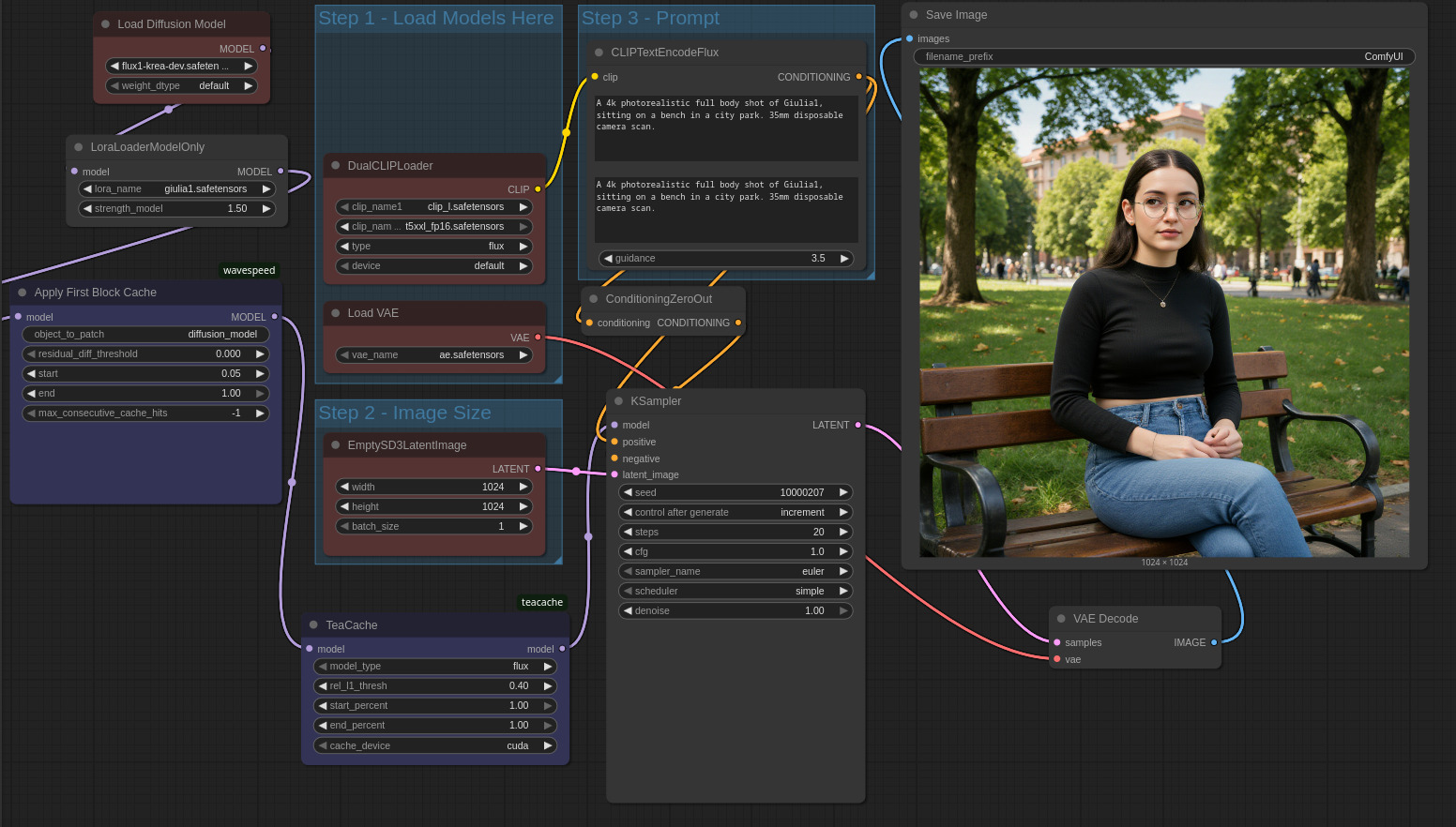
Per cominciare un semplice prompt del tipo A 4k photorealistic full body shot of Giulia1, sitting on a bench in a city park, in 20 step e con il resto delle impostazioni visibili nell’immagine qui sotto, produce un’immagine a tutti gli effetti coerente con quella di partenza: Giulia è rappresentata nell’immagine unicamente grazie al riferimento del nome nel prompt, senza bisogno di specificarne le caratteristiche fisiche / estetiche.
Decido dunque di arricchire un pochino la descrizione nel prompt, specificando l’abbigliamento richiesto per il soggetto (si noti come non si tratti di un outfit presente nel dataset di training) e un’azione in corso (lavoro al computer portatile): il risultato è ancora più che buono in termini di coerenza, proporzioni, credibilità dell’espressione e aderenza al prompt.
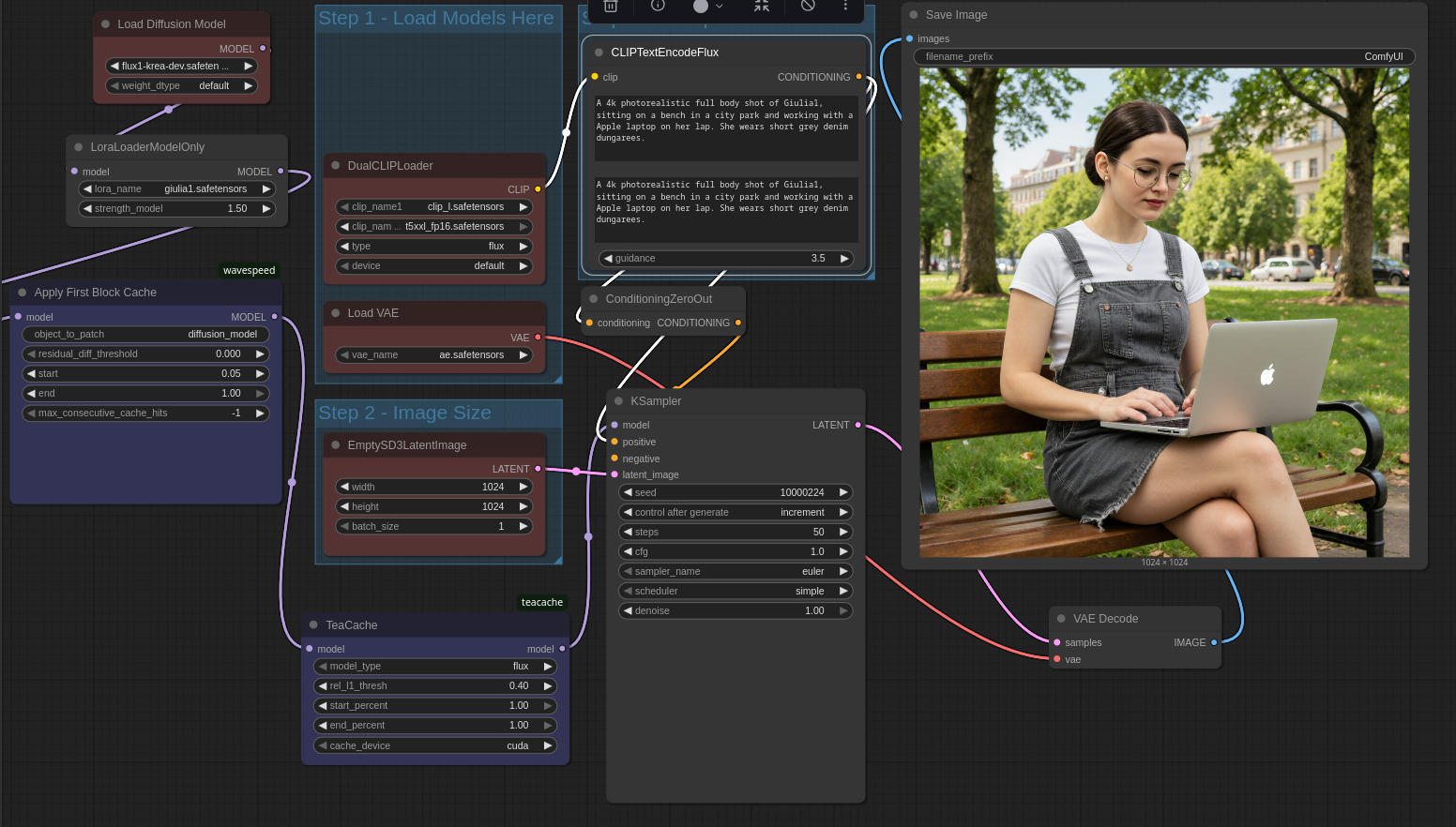
Noto tuttavia che i tatuaggi alle gambe sembrano scomparsi (avevo esplicitamente fornito un’immagine ravvicinata nel dataset di training, per valutare le capacità di imparare dettagli complessi). Provo dunque a “dare una mano” al modello, esplicitando nel prompt la presenza dei tatuaggi alle gambe.
💡 Suggerimento prompt: talvolta parte del prompt non viene recepito correttamente. Nell’esempio qui sopra, Giulia lavora effettivamente al portatile, etc. ma a voler essere pignoli l’immagine generata non è veramente
a full body shot. Un modo elegante per forzare il modello a rispettare la richiesta è quello di aggiungere del dettaglio informativo nel prompt - e dunque nel contesto - riguardo la parte dell’immagine che sta venendo ignorata, in questo caso i piedi del soggetto. Aggiungo quindi informazioni sul tipo di scarpe da generare.
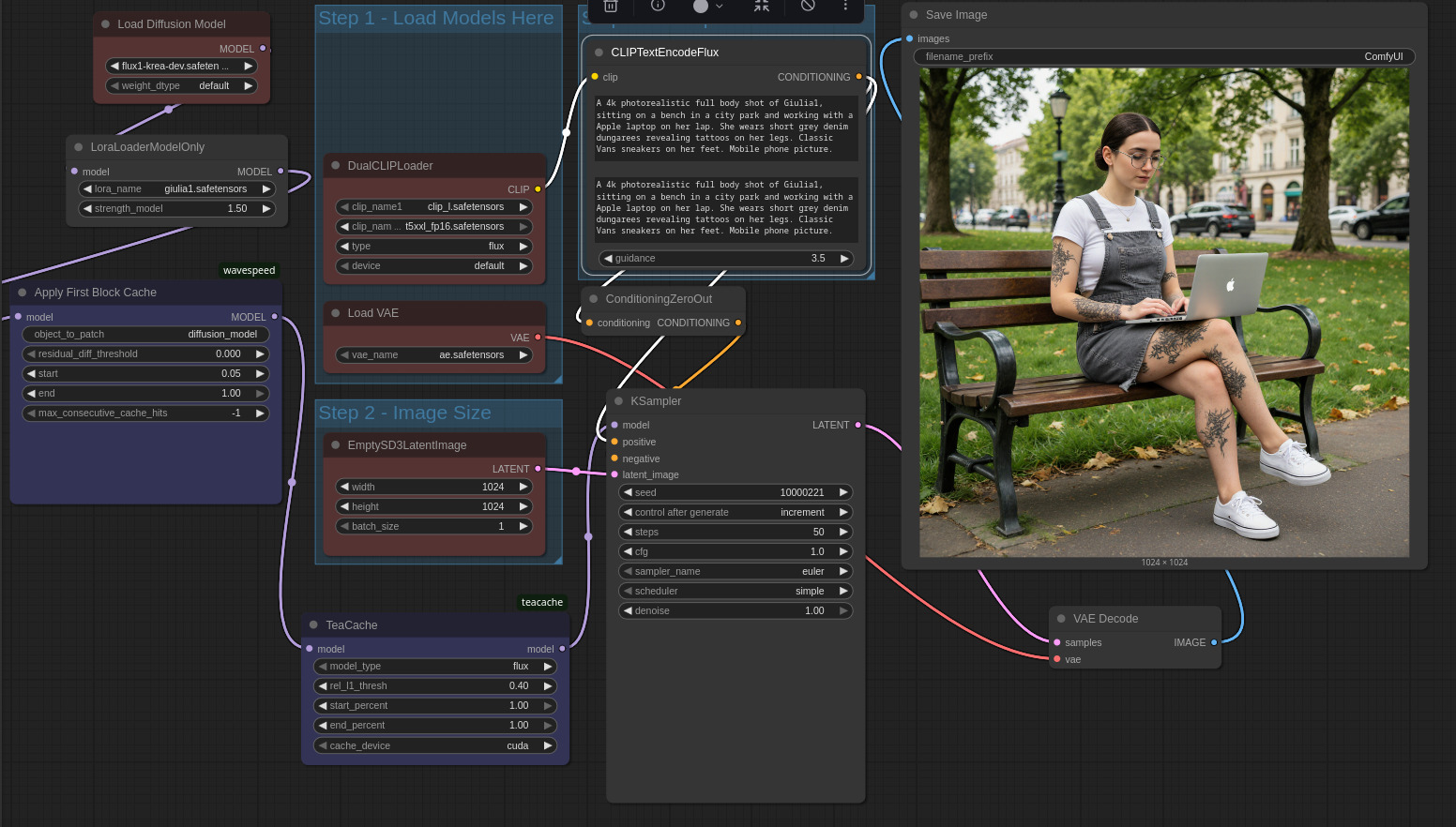
Con il prompt rivisto otteniamo i tatuaggi richiesti. Il LoRA sembra avere effettivamente imparato qualcosa riguardo i tatuaggi di Giulia, le posizioni sulle gambe sono corrette, il colore è giusto, lo stile / pattern tuttavia è simile ma non identico (indice della necessità di migliori e più numerose immagini necessarie nel dataset e probabilmente di una fase di training più estesa e meglio configurata). Inoltre, l’immagine generata presenta tatuaggi non richiesti anche sulle braccia.
Per concludere provo ad utilizzare un prompt molto verboso reperito su una galleria online di immagini AI; la scena descritta è relativamente complessa e ricca di dettagli, ciononostante il risultato è sempre più che buono.
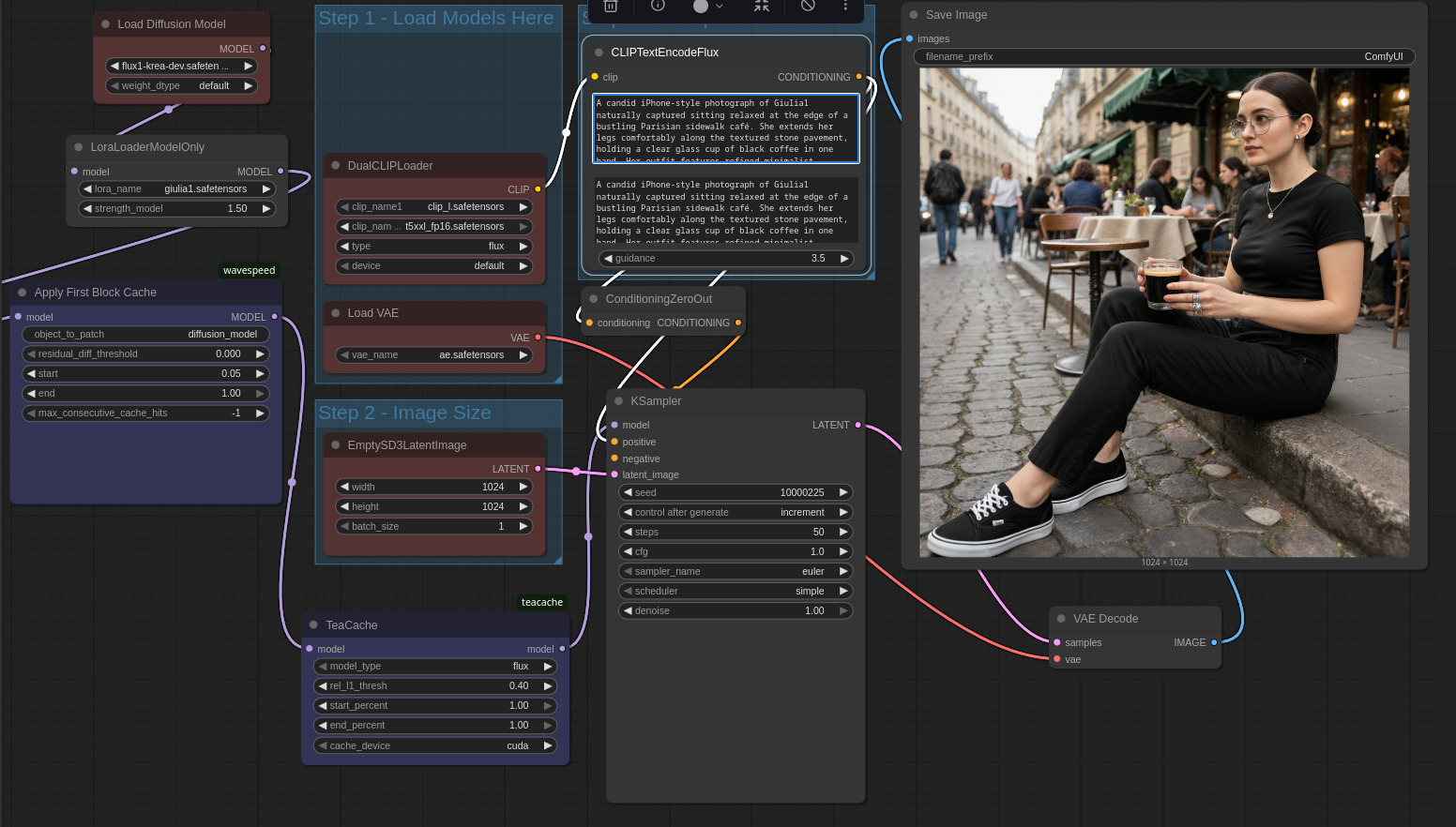
💡 Suggerimento adattamento prompt con LoRA: quando si riutilizza un prompt creato in precedenza, aggiungendo un LoRA e attivandolo con opportuna parola chiave, è opportuno verificare che il prompt non contenga informazioni palesemente in contrasto con gli elementi salienti / distintivi del “soggetto codificato” nel LoRA. Se il soggetto ha capelli corti, per dire, un prompt che descrive i capelli che cadono lungo la schiena del soggetto, porta facilmente ad una generazione che non rappresenta correttamente il soggetto del LoRA o che non rispetta le richieste del prompt.
Conclusioni: cosa ho imparato (e perché questo esperimento conta)
Questo esperimento non è un tutorial “perfetto”. Non ho:
- selezionato un dataset ottimale;
- sistemato le caption (spesso inaccurate);
- fatto upscaling serio di tutte le immagini;
- bilanciato LR, repeats, rank del LoRA;
- iterato su 3–4 training per confrontare risultati.
Eppure, con:
- una sola immagine iniziale,
- ~25 immagini derivate,
- un training leggero in locale,
- un modello Flux in locale,
sono riuscito a creare un personaggio consistente, da zero, completamente offline, e senza censure.
È una cosa incredibile sia in positivo (creatività, prototipazione, storytelling, produzione veloce di contenuti), sia in negativo:
il sistema funziona anche con foto vere di persone reali.
E questo costringe ognuno di noi a rivalutare l’autenticità di praticamente qualunque contenuto visuale trovato online.
Non escludo un domani di approfondire la configurazione dell’addestramento LoRA, per ora tuttavia mi fermo qui: un flusso, realmente provato, che partendo da un singolo scatto permette di generare qualunque scena con un personaggio inventato — ma coerente.